The Go Blog
Go で LLM を活用したアプリケーションを構築する
LLM (大規模言語モデル) と埋め込みモデルのような隣接ツールの機能が過去 1 年間で大幅に向上したため、ますます多くの開発者が LLM をアプリケーションに統合することを検討しています。
LLM は専用のハードウェアとかなりの計算リソースを必要とすることが多いため、アクセス用の API を提供するネットワーク サービスとしてパッケージ化されるのが一般的です。OpenAI や Google Gemini のような主要な LLM の API はこのように機能します。Ollama のような「自分で LLM を実行する」ツールでさえ、ローカル消費のために LLM を REST API でラップしています。さらに、アプリケーションで LLM を利用する開発者は、ベクトル データベースのような補助ツールを必要とすることが多く、これらもネットワーク サービスとしてデプロイされるのが一般的です。
言い換えれば、LLM を活用したアプリケーションは、他の最新のクラウドネイティブ アプリケーションと非常によく似ています。REST および RPC プロトコル、並行処理、パフォーマンスに対する優れたサポートを必要とします。これらは Go が得意とする分野であり、Go を LLM を活用したアプリケーションを記述するのに最適な言語にしています。
このブログ記事では、Go を使用したシンプルな LLM を活用したアプリケーションの例を説明します。まず、デモ アプリケーションが解決する問題を説明し、次に、同じタスクを実行するが、異なるパッケージを使用して実装するアプリケーションのいくつかのバリエーションを提示します。この記事のデモのすべてのコードはオンラインで入手できます。
Q&A 用の RAG サーバー
一般的な LLM を活用したアプリケーション技術は RAG - Retrieval Augmented Generation です。RAG は、ドメイン固有の対話のために LLM の知識ベースをカスタマイズする最もスケーラブルな方法の 1 つです。
Go でRAG サーバーを構築します。これは、ユーザーに 2 つの操作を提供する HTTP サーバーです。
- 知識ベースにドキュメントを追加する
- この知識ベースについて LLM に質問する
典型的な実際のシナリオでは、ユーザーはドキュメントのコーパスをサーバーに追加し、質問を続行します。たとえば、企業は RAG サーバーの知識ベースに社内ドキュメントを入力し、それを使用して社内ユーザーに LLM を活用した Q&A 機能を提供できます。
サーバーと外部世界との相互作用を示す図を次に示します。
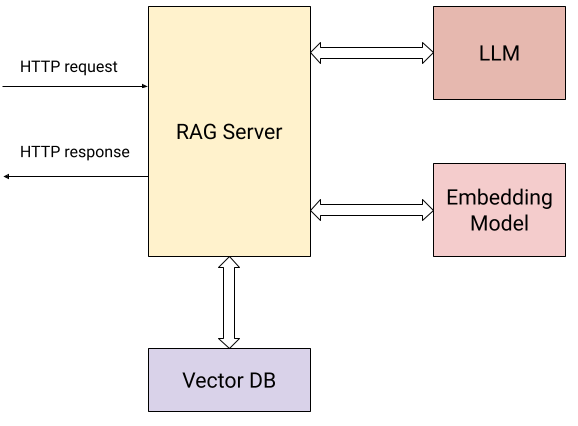
ユーザーが HTTP リクエストを送信する (上記の 2 つの操作) だけでなく、サーバーは以下と対話します。
- 送信されたドキュメントとユーザーの質問のベクトル埋め込みを計算するための埋め込みモデル。
- 埋め込みを効率的に保存および取得するためのベクトル データベース。
- 知識ベースから収集されたコンテキストに基づいて質問を行うための LLM。
具体的には、サーバーはユーザーに 2 つの HTTP エンドポイントを公開します。
/add/: POST {"documents": [{"text": "..."}, {"text": "..."}, ...]}: サーバーにテキスト ドキュメントのシーケンスを送信し、知識ベースに追加します。このリクエストの場合、サーバーは次の処理を行います。
- 埋め込みモデルを使用して各ドキュメントのベクトル埋め込みを計算します。
- ドキュメントとそれらのベクトル埋め込みをベクトル DB に保存します。
/query/: POST {"content": "..."}: サーバーに質問を送信します。このリクエストの場合、サーバーは次の処理を行います。
- 埋め込みモデルを使用して質問のベクトル埋め込みを計算します。
- ベクトル DB の類似度検索を使用して、知識データベース内の質問に最も関連性の高いドキュメントを見つけます。
- シンプルなプロンプト エンジニアリングを使用して、ステップ (2) で見つかった最も関連性の高いドキュメントをコンテキストとして質問を再構成し、それを LLM に送信し、その回答をユーザーに返します。
デモで使用されるサービスは次のとおりです。
- LLM および埋め込みモデル用のGoogle Gemini API。
- ローカルでホストされるベクトル DB 用のWeaviate。Weaviate はGo で実装されたオープンソースのベクトル データベースです。
これらを他の同等のサービスに置き換えるのは非常に簡単です。実際、これはサーバーの 2 番目と 3 番目のバリアントのすべてです!これらのツールを直接使用する最初のバリアントから始めます。
Gemini API と Weaviate を直接使用する
Gemini API と Weaviate の両方には便利な Go SDK (クライアント ライブラリ) があり、最初のサーバー バリアントはこれらを直接使用します。このバリアントの完全なコードはこのディレクトリにあります。
このブログ記事ではコード全体を再現しませんが、読む際に心に留めておくべきいくつかの点があります。
構造: コード構造は、Go で HTTP サーバーを作成したことがある人にはおなじみでしょう。Gemini と Weaviate のクライアント ライブラリが初期化され、クライアントは HTTP ハンドラーに渡される状態値に保存されます。
ルート登録: サーバーの HTTP ルートは、Go 1.22 で導入されたルーティング強化を使用して簡単に設定できます。
mux := http.NewServeMux()
mux.HandleFunc("POST /add/", server.addDocumentsHandler)
mux.HandleFunc("POST /query/", server.queryHandler)
並行処理: サーバーの HTTP ハンドラーは、ネットワークを介して他のサービスにアクセスし、応答を待ちます。各 HTTP ハンドラーは独自のゴルーチンで並行して実行されるため、これは Go にとって問題ではありません。この RAG サーバーは多数の同時リクエストを処理でき、各ハンドラーのコードは線形かつ同期です。
バッチ API: /add/ リクエストは知識ベースに追加する多数のドキュメントを提供する場合があるため、サーバーは埋め込み (embModel.BatchEmbedContents) と Weaviate DB (rs.wvClient.Batch) の両方でバッチ API を活用して効率を高めています。
LangChain for Go を使用する
2 番目の RAG サーバー バリアントは LangChainGo を使用して同じタスクを実行します。
LangChain は、LLM を活用したアプリケーションを構築するための人気のある Python フレームワークです。LangChainGo はその Go 版です。このフレームワークには、モジュール化されたコンポーネントからアプリケーションを構築するためのツールがあり、多くの LLM プロバイダーとベクトル データベースを共通の API でサポートしています。これにより、開発者は任意のプロバイダーで動作するコードを記述し、プロバイダーを非常に簡単に変更できます。
このバリアントの完全なコードはこのディレクトリにあります。コードを読むと、2 つのことに気づくでしょう。
まず、以前のバリアントよりも多少短くなっています。LangChainGo は、ベクトル データベースの完全な API を共通のインターフェイスにラップする処理を行うため、Weaviate の初期化と処理に必要なコードが少なくなっています。
次に、LangChainGo API を使用すると、プロバイダーを簡単に切り替えることができます。Weaviate を別のベクトル DB に置き換えたいとします。以前のバリアントでは、ベクトル DB と連携するすべてのコードを新しい API を使用するように書き直す必要がありました。LangChainGo のようなフレームワークを使用すると、その必要がなくなります。LangChainGo が関心のある新しいベクトル DB をサポートしている限り、すべての DB が共通のインターフェイスを実装しているため、サーバーの数行のコードを置き換えるだけで済みます。
type VectorStore interface {
AddDocuments(ctx context.Context, docs []schema.Document, options ...Option) ([]string, error)
SimilaritySearch(ctx context.Context, query string, numDocuments int, options ...Option) ([]schema.Document, error)
}
Genkit for Go を使用する
今年初め、Google は Genkit for Go を発表しました。これは、LLM を活用したアプリケーションを構築するための新しいオープンソース フレームワークです。Genkit は LangChain といくつかの共通の特性を共有していますが、他の側面では異なります。
LangChain と同様に、異なるプロバイダー (プラグインとして) によって実装される可能性のある共通のインターフェイスを提供するため、あるプロバイダーから別のプロバイダーへの切り替えが簡単になります。ただし、異なる LLM コンポーネントがどのように相互作用するかを規定しようとはしません。代わりに、プロンプト管理やエンジニアリング、統合開発者ツールによるデプロイなどの本番機能に焦点を当てています。
3 番目の RAG サーバー バリアントは Genkit for Go を使用して同じタスクを実行します。その完全なコードはこのディレクトリにあります。
このバリアントは LangChainGo のものとかなり似ています。LLM、埋め込みモデル、ベクトル DB の共通インターフェイスが直接プロバイダー API の代わりに使用されており、あるものから別のものへの切り替えが簡単になります。さらに、LLM を活用したアプリケーションを本番環境にデプロイするのは Genkit を使用するとずっと簡単です。このバリアントではこれを実装していませんが、興味がある場合はドキュメントを自由に読んでください。
まとめ - LLM を活用したアプリケーション向けの Go
この記事のサンプルは、Go で LLM を活用したアプリケーションを構築できる可能性のほんの一部を示しています。比較的少ないコードで強力な RAG サーバーを構築するのがいかに簡単かを示しています。最も重要なのは、Go のいくつかの基本的な機能により、サンプルがかなりの本番対応度を備えていることです。
LLM サービスと連携するということは、多くの場合、ネットワーク サービスに REST または RPC リクエストを送信し、応答を待ち、それに基づいて他のサービスに新しいリクエストを送信するなどを意味します。Go はこれらのすべてに優れており、並行処理とネットワーク サービスのやりくりという複雑さを管理するための優れたツールを提供します。
さらに、Go はクラウドネイティブ言語としての優れたパフォーマンスと信頼性により、LLM エコシステムのより基本的な構成要素を実装するための自然な選択肢となります。いくつかの例については、Ollama、LocalAI、Weaviate、Milvus などのプロジェクトを参照してください。
次の記事: エイリアス名とは何か?
前の記事: Go での開発に関するフィードバックを共有してください
ブログインデックス