The Go Blog
Getting to Go: Goのガベージコレクタの旅
これは、2018年6月18日にInternational Symposium on Memory Management (ISMM)で行った基調講演の原稿です。過去25年間、ISMMはメモリ管理とガベージコレクションに関する論文を発表する主要な場であり、基調講演に招待されたことは光栄でした。
概要
Go言語の機能、目標、ユースケースは、ガベージコレクションスタック全体を再考することを余儀なくさせ、私たちを驚くべき場所に導きました。この旅は爽快でした。この講演では、私たちの旅について説明します。オープンソースとGoogleの生産要求に動機付けられた旅です。数字が私たちを家に導いた袋小路の渓谷への寄り道も含まれています。この講演は、私たちの旅の経緯と理由、2018年の現在地、そして次の旅に向けたGoの準備について洞察を提供します。
略歴
リチャード・L・ハドソン(リック)は、Train、Sapphire、Mississippi Deltaアルゴリズムの発明を含むメモリ管理の仕事や、Modula-3、Java、C#、Goなどの静的型付け言語でのガベージコレクションを可能にしたGCスタックマップで最もよく知られています。リックは現在、GoogleのGoチームのメンバーであり、Goのガベージコレクションとランタイムの問題に取り組んでいます。
連絡先:rlh@golang.org
コメント:golang-devでの議論を参照してください。
講演録

リック・ハドソンです。
これはGoランタイム、特にガベージコレクタについての講演です。約45〜50分の準備資料があり、その後は質疑応答の時間がありますので、講演後もご自由に話しかけてください。

始める前に、何人かの人々に感謝したいと思います。
講演の多くの素晴らしい部分はオースティン・クレメンツが行いました。ケンブリッジGoチームの他のメンバー、ラス、サン、チェリー、デビッドは、協力的で刺激的で楽しいグループでした。
また、世界中の160万人のGoユーザーに、興味深い問題を提供してくれたことに感謝します。彼らがいなければ、これらの問題の多くは決して表面化しなかったでしょう。
最後に、長年にわたり素晴らしいGopherたちを生み出してきたレネ・フレンチに感謝したいと思います。講演中にいくつか見かけるでしょう。

この話を進める前に、GCから見たGoの姿を本当に示す必要があります。

まず、Goプログラムには数十万のスタックがあります。これらはGoスケジューラによって管理され、常にGCセーフポイントでプリエンプトされます。GoスケジューラはGoルーチンをOSスレッドに多重化し、OSスレッドは望ましくはHWスレッドごとに1つのOSスレッドで実行されます。スタックとそのサイズは、コピーしてスタック内のポインタを更新することで管理します。これはローカルな操作なので、かなりうまくスケーリングします。

次に重要なのは、Goがほとんどのマネージドランタイム言語の伝統における参照指向言語ではなく、Cライクなシステム言語の伝統における値指向言語であるという事実です。例えば、これはtarパッケージの型がメモリにどのように配置されるかを示しています。すべてのフィールドはReader値に直接埋め込まれています。これにより、プログラマーは必要に応じてメモリレイアウトをより細かく制御できます。関連する値を持つフィールドを同じ場所に配置することができ、これはキャッシュの局所性に役立ちます。
値指向は、外部関数インターフェースにも役立ちます。CおよびC++との高速FFIがあります。明らかにGoogleには膨大な施設がありますが、それらはC++で書かれています。GoはこれらすべてをGoで再実装するのを待てなかったため、Goは外部関数インターフェースを介してこれらのシステムにアクセスする必要がありました。
この設計上の決定の1つは、ランタイムで発生しなければならないより驚くべきことのいくつかにつながりました。これはおそらく、Goを他のGC言語と区別する最も重要なことです。
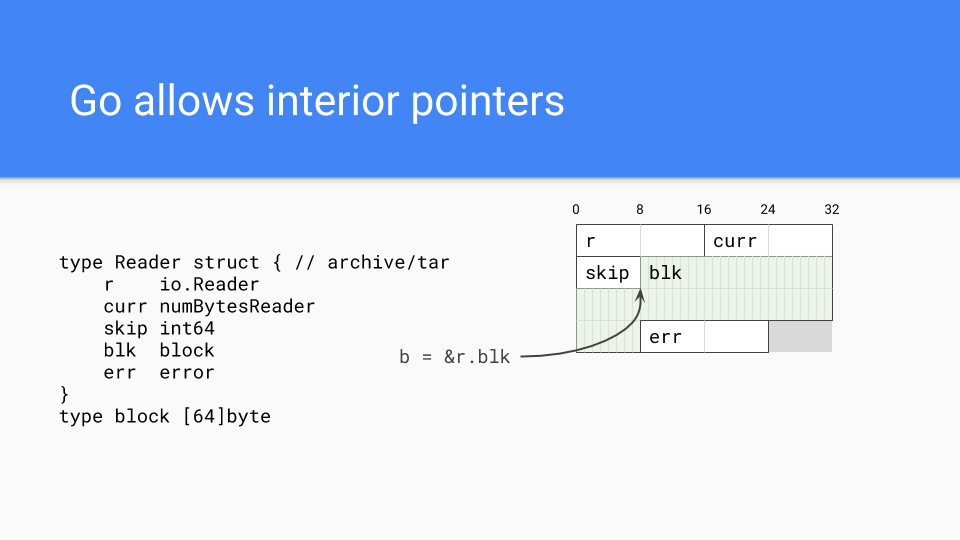
もちろん、Goはポインタを持つことができ、実際には内部ポインタを持つことができます。このようなポインタは値全体をライブ状態に保ち、かなり一般的です。

また、事前コンパイルシステムも用意されているため、バイナリにはランタイム全体が含まれています。
JIT再コンパイルはありません。これには長所と短所があります。まず、プログラム実行の再現性がはるかに容易になり、コンパイラの改善をはるかに迅速に進めることができます。
残念なことに、JITシステムのようにフィードバック最適化を行う機会がありません。
したがって、長所と短所があります。

GoにはGCを制御するための2つのつまみがあります。1つ目はGCPercentです。基本的に、これは使用したいCPUの量と使用したいメモリの量を調整するつまみです。デフォルトは100で、これはヒープの半分がライブメモリに、ヒープの半分が割り当てに割り当てられることを意味します。これはどちらの方向にも変更できます。
MaxHeapはまだリリースされていませんが、社内で使用および評価されており、プログラマーが最大ヒープサイズを設定できます。メモリ不足、OOMはGoにとって厳しいです。一時的なメモリ使用量の急増は、中止するのではなく、CPUコストを増やすことで処理する必要があります。基本的に、GCがメモリ圧力を検知すると、アプリケーションに負荷を減らすように通知します。状況が正常に戻ると、GCはアプリケーションに通常の負荷に戻ってよいことを通知します。MaxHeapはスケジューリングにもはるかに柔軟性をもたらします。メモリがどれだけ利用可能かを常に心配するのではなく、ランタイムはヒープをMaxHeapまでサイズ変更できます。
これで、ガベージコレクタにとって重要なGoの要素についての議論は終わりです。

それでは、Goランタイムと、どうしてここまで来たのか、どうやって今の場所にたどり着いたのかについて話しましょう。

2014年のことでした。GoがこのGCレイテンシ問題を何とか解決できなければ、Goは成功しないでしょう。それは明らかでした。
他の新しい言語も同じ問題に直面していました。Rustのような言語は別の道を進みましたが、Goが辿った道について話します。
なぜレイテンシがそれほど重要なのでしょうか?

これに関しては、数学が完全に容赦しません。
99%ileの分離されたGCレイテンシサービスレベル目標(SLO)、「GCサイクルが99%の時間で10ms未満になる」といったものは、単純にスケールしません。重要なのは、セッション全体、または1日に何度もアプリを使用する過程でのレイテンシです。例えば、いくつかのWebページを閲覧するセッションが、セッション中に100回のサーバーリクエストを行うか、または20回のリクエストを行い、1日に5つのセッションが詰め込まれていると仮定します。その状況では、全セッションを通じて一貫して10ms未満の体験を得られるユーザーはわずか37%です。
推奨する通り、これらのユーザーの99%が10ms未満の体験を望むなら、数学的には4つの9、つまり99.99%ileを目標にする必要があると示されています。
2014年のことです。ジェフ・ディーンが「The Tail at Scale」という論文を発表したばかりで、それがこの問題をさらに深く掘り下げていました。Googleが今後、Google規模でスケーリングを試みる上で重大な影響があったため、Google内で広く読まれていました。
私たちはこの問題を「9の暴政」と呼んでいます。

では、「9の暴政」とどう戦うのか?
2014年には多くのことが行われていました。
10個の答えが欲しいなら、さらにいくつか要求して、最初の10個を取り、それらを検索ページに表示する。リクエストが50%ileを超えたら、リクエストを再発行するか、別のサーバーに転送する。GCが実行されようとしている場合、新しいリクエストを拒否するか、GCが完了するまでリクエストを別のサーバーに転送する。などなど。
これらはすべて、非常に現実的な問題を抱えた非常に賢い人々による回避策ですが、GCレイテンシの根本的な問題には対処していませんでした。Google規模では、根本的な問題に取り組まなければなりませんでした。なぜでしょうか?

冗長性はスケールせず、冗長性には多くのコストがかかります。新しいサーバーファームが必要になります。
私たちはこの問題を解決できると希望し、サーバーエコシステムを改善する機会と捉え、その過程で絶滅の危機に瀕しているいくつかのトウモロコシ畑を救い、いくつかのトウモロコシの粒が7月4日までに膝丈になり、その潜在能力を最大限に発揮できる機会を与えることができると考えました。

これが2014年のSLOです。確かに、私はサボっていました。チームに入ったばかりで、私にとって新しいプロセスだったので、過剰に約束したくありませんでした。
さらに、他の言語におけるGCレイテンシに関するプレゼンテーションは、単純に恐ろしいものでした。

当初の計画は、リードバリアなしの並行コピーGCを行うことでした。それが長期計画でした。リードバリアのオーバーヘッドについては多くの不確実性があったため、Goはそれを避けたかったのです。
しかし、短期的な2014年には、私たちは体制を整える必要がありました。ランタイムとコンパイラをすべてGoに変換しなければなりませんでした。当時それらはCで書かれていました。もうCはなし、GCを理解せずにクールな文字列コピーのアイデアを持つCコーダーによるバグの長い尾もなし。また、迅速に何か必要で、レイテンシに焦点を当てましたが、パフォーマンスの低下はコンパイラによる高速化よりも小さくなければなりませんでした。そのため、私たちは制約されていました。GCを並行にすることで、コンパイラのパフォーマンス改善の約1年分を食い潰すことができました。しかし、それだけでした。Goプログラムを遅くすることはできませんでした。2014年にはそれは維持できませんでした。

そこで、少し後退しました。コピー部分は行わないことにしました。
三色並行アルゴリズムを採用することにしました。私のキャリアの初期に、エリオット・モスと私は、ダイクストラのアルゴリズムが複数のアプリケーションスレッドで機能することを示すジャーナル証明を行いました。また、STW問題を解決できることも示し、それが可能であるという証明も持っていました。
コンパイラの速度、つまりコンパイラが生成するコードについても懸念していました。ライトバリアをほとんどの時間オフにしておけば、コンパイラの最適化への影響は最小限に抑えられ、コンパイラチームは迅速に進むことができます。Goはまた、2015年に短期的な成功を強く必要としていました。
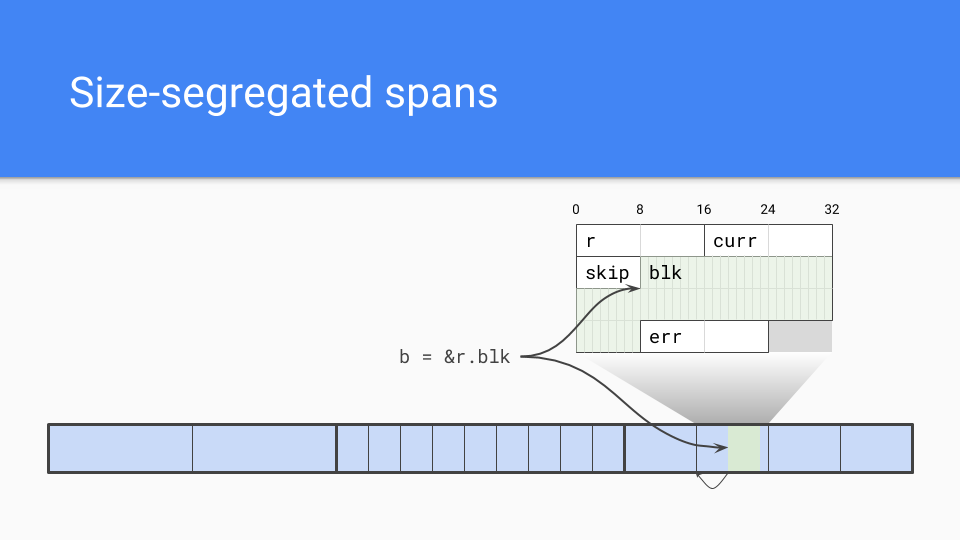
では、私たちが行ったことのいくつかを見てみましょう。
サイズごとに分離されたスパンを採用しました。内部ポインタが問題でした。
ガベージコレクタは、オブジェクトの開始位置を効率的に見つける必要があります。スパン内のオブジェクトのサイズを知っていれば、そのサイズに切り捨てるだけで、それがオブジェクトの開始位置になります。
もちろん、サイズごとに分離されたスパンには、他にもいくつかの利点があります。
低い断片化:Cの経験、GoogleのTCMallocとHoard以外に、私はIntelのScalable Mallocに深く関わっており、その仕事のおかげで、非移動型アロケータでの断片化は問題にならないと確信していました。
内部構造:それらを完全に理解し、経験していました。サイズごとに分離されたスパンの作成方法、低またはゼロ競合の割り当てパスの作成方法を理解していました。
速度:非コピーは懸念事項ではありませんでした。割り当ては確かに遅くなるかもしれませんが、Cのオーダーにとどまります。バンプポインタほど速くはないかもしれませんが、それは問題ありませんでした。
また、外部関数インターフェースの問題もありました。オブジェクトを移動させなければ、オブジェクトを固定し、Cと作業中のGoオブジェクトの間に間接参照レベルを置こうとする移動コレクタで発生する可能性のあるバグの長い尾に対処する必要がありませんでした。

次の設計選択は、オブジェクトのメタデータをどこに置くかでした。ヘッダーがなかったため、オブジェクトに関する情報が必要でした。マークビットは脇に置かれ、マーキングと割り当ての両方に使用されます。各ワードには2ビットが関連付けられており、それがスカラかそのワード内のポインタかを示します。また、オブジェクト内にもっとポインタがあるかどうかをエンコードし、オブジェクトのスキャンを早く停止できるようにしました。さらに、追加のマークビットとして、または他のデバッグ作業に使用できる追加のビットエンコーディングもありました。これは、この機能の実行とバグの発見に非常に役立ちました。

では、ライトバリアはどうでしょうか?ライトバリアはGC中のみオンになります。それ以外の時間では、コンパイルされたコードはグローバル変数を読み込み、それを参照します。GCは通常オフなので、ハードウェアはライトバリアを回避するように正しく投機的に分岐します。GC内部ではその変数は異なり、ライトバリアは三色操作中に到達可能なオブジェクトが失われないことを保証する役割を担っています。

このコードのもう1つの部分はGC Pacerです。これはオースティンが行った素晴らしい仕事の一部です。基本的には、GCサイクルを開始する最適なタイミングを決定するフィードバックループに基づいています。システムが安定状態にあり、フェーズ変更中でない場合、マーキングはメモリが尽きるのとほぼ同時に終了します。
そうでない場合もあるため、Pacerはマーキングの進捗状況も監視し、割り当てが並行マーキングをオーバーランしないようにする必要があります。
必要に応じて、Pacerは割り当てを遅くし、マーキングを加速させます。高レベルでは、Pacerは多くの割り当てを行っているGoroutineを停止させ、マーキング作業に割り当てます。作業量はGoroutineの割り当てに比例します。これにより、ガベージコレクタは高速化され、ミューテーターは遅くなります。
これらすべてが完了すると、Pacerは現在のGCサイクルと以前のサイクルから学んだことを基に、次のGCを開始する時期を予測します。
これよりもはるかに多くのことを行いますが、それが基本的なアプローチです。
数学は絶対に魅力的です。設計ドキュメントについては私にpingを送ってください。並行GCを行っているなら、この数学を見て、それがあなたの数学と同じかどうかを確認する義務があります。何か提案があれば教えてください。
*Go 1.5並行ガベージコレクタのペース調整および提案:ソフトヒープとハードヒープサイズの目標を分離する

そうです、成功を収めました。たくさん。若くて無謀だった頃のリックなら、これらのグラフのいくつかを肩にタトゥーとして入れたことでしょう。それほど誇りに思っていました。
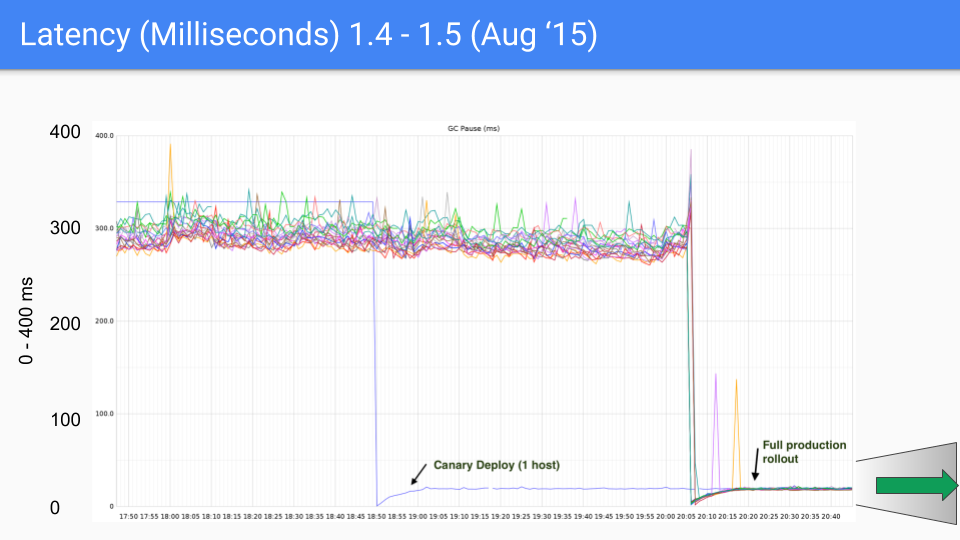
これは、Twitterのプロダクションサーバーのために作成された一連のグラフです。もちろん、私たちはそのプロダクションサーバーとは何の関係もありませんでした。ブライアン・ハットフィールドがこれらの測定を行い、不思議なことにそれらについてツイートしました。
Y軸はGCレイテンシをミリ秒単位で表しています。X軸は時間を表しています。各点は、そのGC中のストップザワールドの一時停止時間です。
2015年8月の最初のリリースでは、300〜400ミリ秒だったレイテンシが30〜40ミリ秒に低下しました。これは良かった、桁違いに良かった。
ここでY軸を0から400ミリ秒から0から50ミリ秒に根本的に変更します。
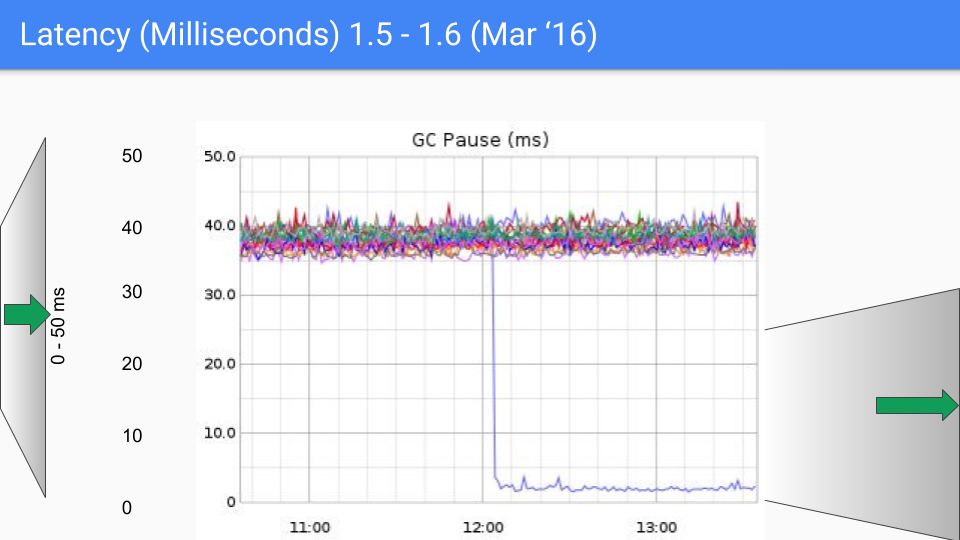
これは6ヶ月後のことです。改善は主に、ストップザワールド中に私たちが行っていたO(ヒープ)なことをすべて体系的に排除したことによるものでした。これは、40ミリ秒から4〜5ミリ秒へと、2回目の桁違いの改善でした。
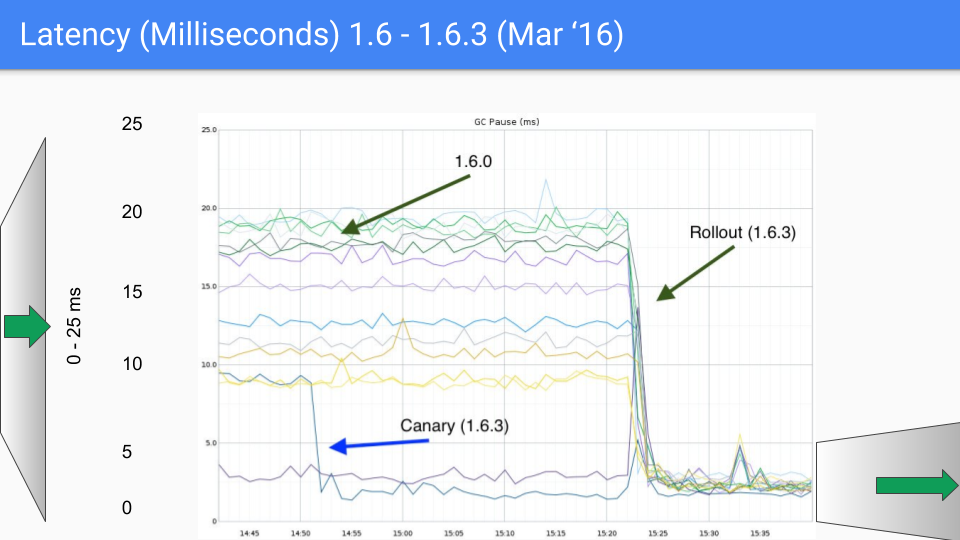
そこには修正すべきバグがいくつかあり、マイナーリリース1.6.3でこれを行いました。これにより、レイテンシはSLOであった10ミリ秒を大幅に下回りました。
Y軸を再び変更しようとしています。今回は0〜5ミリ秒です。
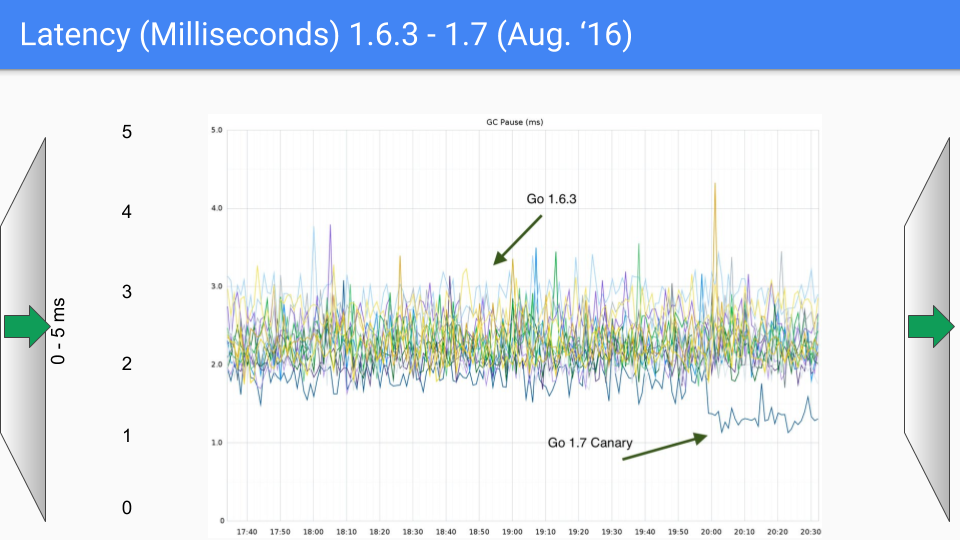
2016年8月、最初のリリースから1年後です。ここでもO(ヒープサイズ)のストップザワールドプロセスを排除し続けました。ここでは18Gバイトのヒープについて話しています。私たちはもっと大きなヒープを持っていました。そして、これらのO(ヒープサイズ)のストップザワールドポーズを排除するにつれて、ヒープサイズは明らかにレイテンシに影響を与えることなく大幅に成長することができました。したがって、これは1.7で少し役に立ちました。
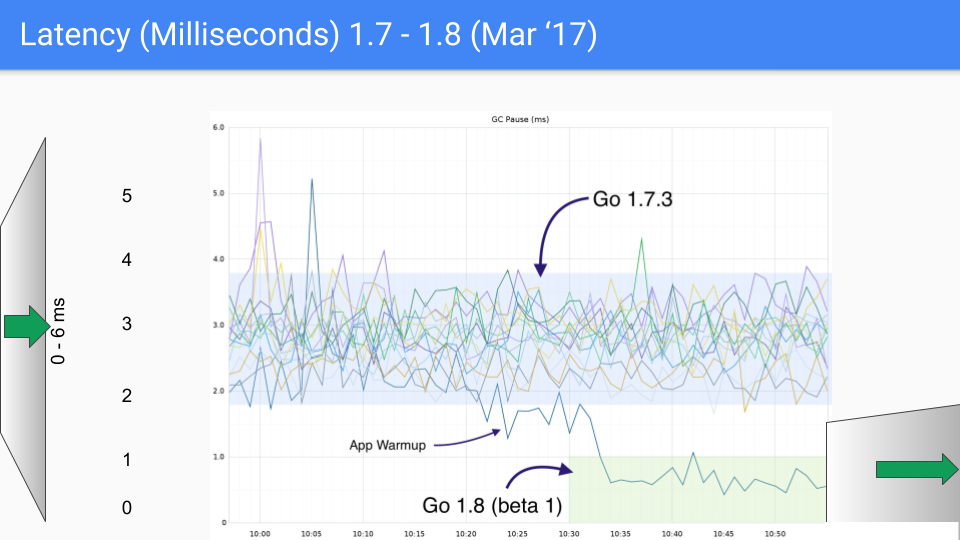
次のリリースは2017年3月でした。GCサイクルの終わりにストップザワールドのスタックスキャンを回避する方法を見つけたことで、最後の大きなレイテンシ低下がありました。これにより、ミリ秒未満の範囲に落ち込みました。再びY軸は1.5ミリ秒に変更され、3桁目の改善が見られます。
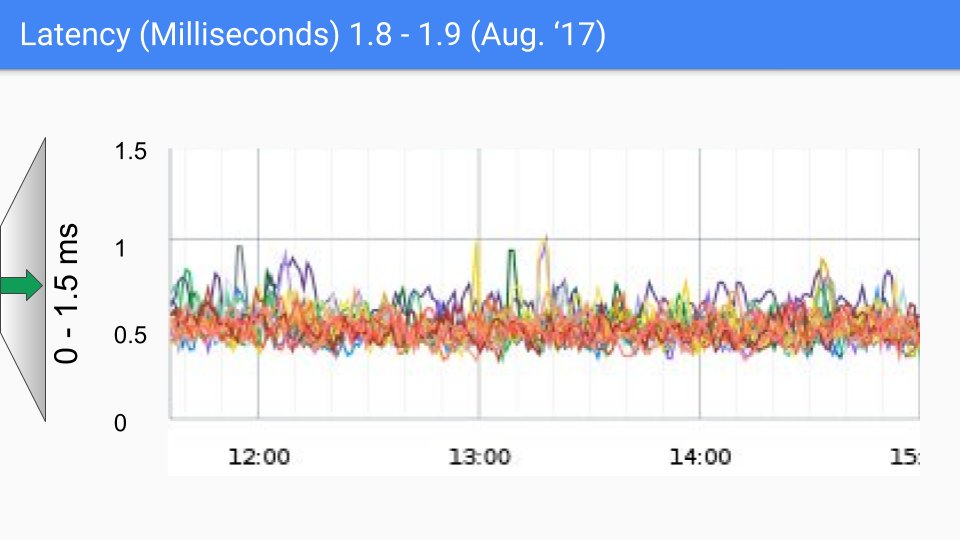
2017年8月のリリースでは、ほとんど改善が見られませんでした。残りの一時停止の原因はわかっています。ここのSLOの囁きの数字は100-200マイクロ秒程度であり、それに向けて推進していきます。もし200マイクロ秒を超えるものが見つかった場合、私たちは本当にあなたと話して、それが私たちが知っていることに当てはまるのか、それともまだ調べていない新しいものなのかを突き止めたいと思っています。いずれにせよ、より低いレイテンシを求める声はほとんどないようです。これらのレイテンシレベルは、GC以外の様々な理由で発生する可能性があることに注意することが重要です。そして、「熊より速く走る必要はない、隣の男より速く走ればいい」という諺にもあるようにです。
2018年2月の1.10リリースでは、いくつかのクリーンアップと例外処理の追い込み以外に実質的な変更はありませんでした。

新年、そして新しいSLO。これが2018年のSLOです。
GCサイクル中に使用されるCPUの総数を削減しました。
ヒープはまだ2倍です。
現在、GCサイクルあたり500マイクロ秒のストップ・ザ・ワールド一時停止を目標としています。おそらくここでは少しサボっています。
割り当ては引き続きGCアシストに比例します。
Pacerはずっと改善されたので、安定状態でのGCアシストは最小限に抑えられました。
私たちはこれにかなり満足していました。繰り返しますが、これはSLAではなくSLOなので、目標であり、合意ではありません。OSのようなものを制御できないからです。

それは良い話でした。話を転換して、私たちの失敗について話しましょう。これらは私たちの傷跡です。タトゥーのようなもので、誰もが持っています。とにかく、それらはより良い物語を伴うので、いくつか話しましょう。

最初の試みは、リクエスト指向コレクタ(ROC)と呼ばれるものを行うことでした。その仮説はここに示されています。

では、これは何を意味するのでしょうか?
GoルーチンはGopherのように見える軽量スレッドなので、ここに2つのGoルーチンがあります。真ん中にある2つの青いオブジェクトのような共有物があります。それぞれ独自のプライベートスタックとプライベートオブジェクトの選択を持っています。例えば、左側の人が緑色のオブジェクトを共有したいとします。
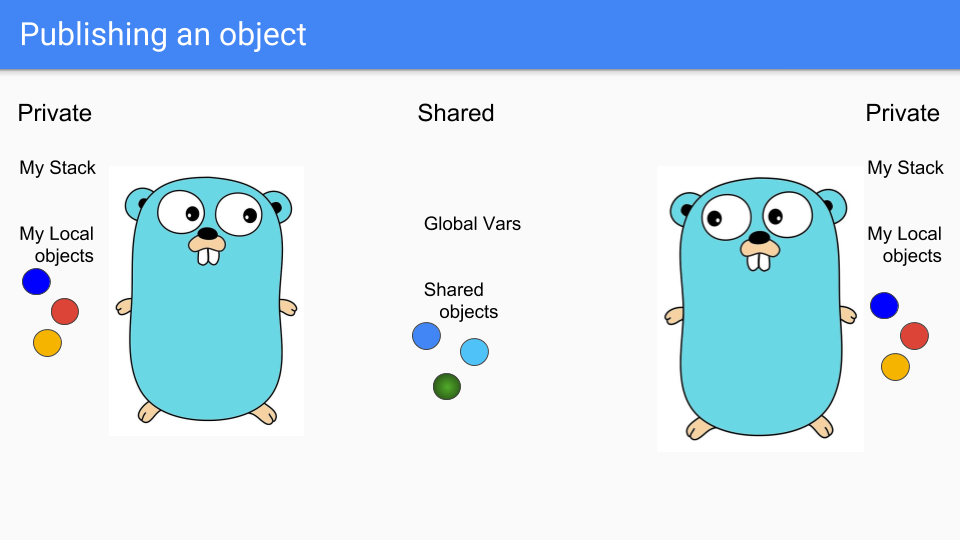
Goルーチンはそれを共有エリアに置き、他のGoルーチンがそれにアクセスできるようにします。共有ヒープの何かにフックしたり、グローバル変数に割り当てたりすることができ、他のGoルーチンはそれを見ることができます。

最後に、左側のGoルーチンは死の床に向かいます。死が近づいています。悲しいことです。
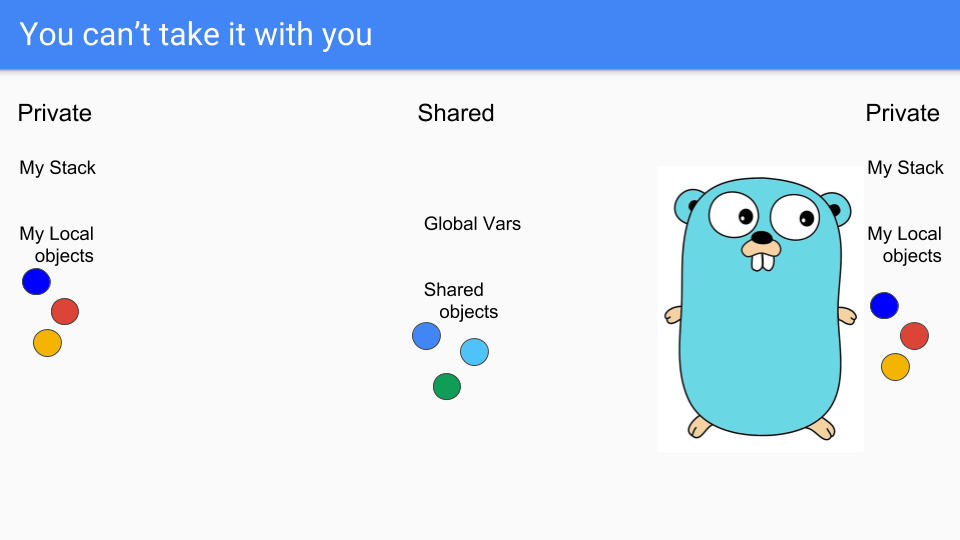
ご存じのとおり、死んだらオブジェクトを持っていくことはできません。スタックも持っていくことはできません。この時、スタックは実際には空で、オブジェクトは到達不可能なので、単純に回収できます。

ここで重要なのは、すべての操作がローカルであり、グローバルな同期を必要としないことでした。これは世代別GCのようなアプローチとは根本的に異なり、この同期を行う必要がないことによって得られるスケーリングが私たちに勝利をもたらすのに十分であるという希望がありました。

このシステムで起きていたもう一つの問題は、ライトバリアが常にオンであったことです。書き込みがあるたびに、それがプライベートオブジェクトへのポインタをパブリックオブジェクトに書き込んでいるかどうかを確認する必要がありました。もしそうであれば、参照されているオブジェクトをパブリックにし、到達可能なオブジェクトを推移的にたどって、それらもパブリックであることを確認する必要がありました。これは非常に高価なライトバリアであり、多くのキャッシュミスを引き起こす可能性がありました。
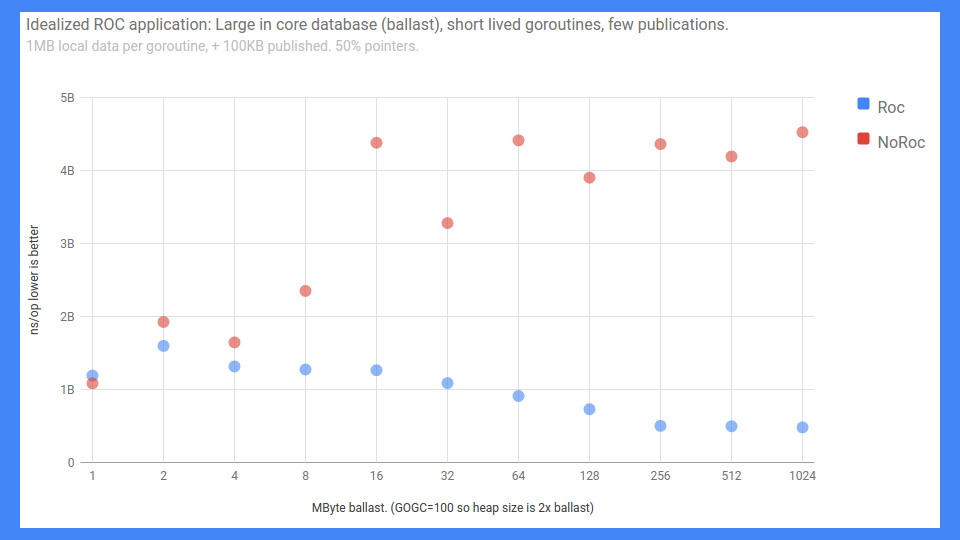
そうは言っても、すごい、かなりの成功を収めました。
これはエンドツーエンドのRPCベンチマークです。誤ったラベルのY軸は0から5ミリ秒まで(低い方が良い)ですが、とにかくそれが実態です。X軸は基本的にバラスト、つまりインコアデータベースの大きさです。
ご覧のとおり、ROCをオンにして共有があまりない場合、物事は実際には非常にうまくスケールします。ROCをオンにしなかった場合は、それほど良くありませんでした。
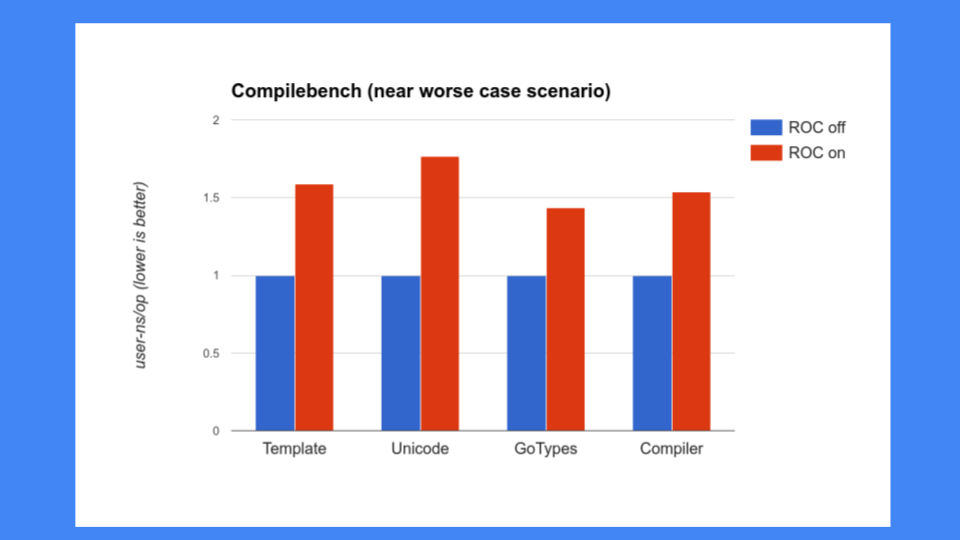
しかし、それでは十分ではありませんでした。ROCがシステムの他の部分を遅くしないことも確認する必要がありました。当時、コンパイラについて多くの懸念があり、コンパイラを遅くすることはできませんでした。残念ながら、コンパイラはROCがうまく機能しないプログラムそのものでした。30、40、50%以上の速度低下が見られ、これは許容できませんでした。Goはコンパイラの速度を誇りに思っているため、コンパイラを遅くすることはできませんでした。特にこれほどは。
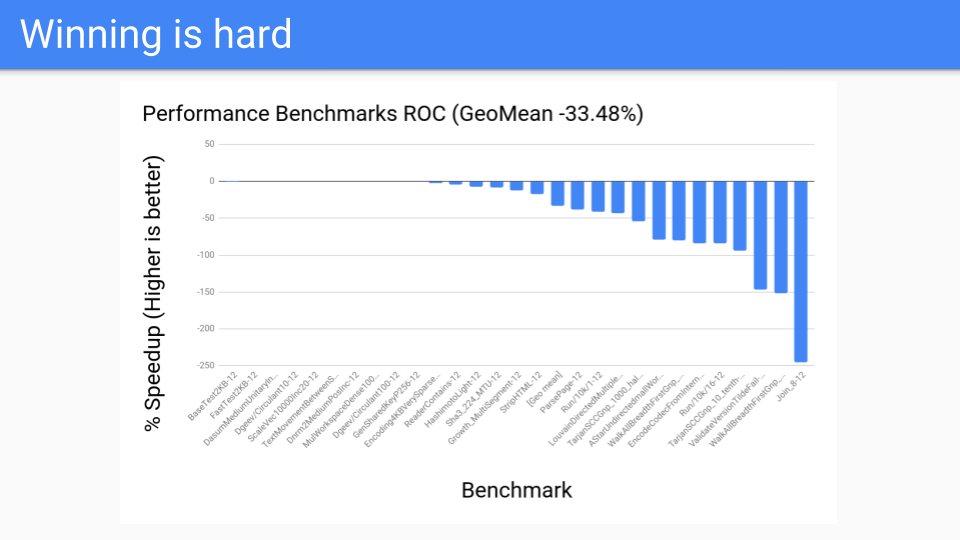
その後、他のプログラムをいくつか見てみました。これらは私たちの性能ベンチマークです。200〜300のベンチマークのコーパスがあり、これらはコンパイラチームが取り組んで改善するために重要だと判断したものだけでした。これらはGCチームによって選ばれたものではありません。数値は一様に悪く、ROCは勝者にはなりませんでした。

確かにスケールしましたが、ハードウェアスレッドシステムは4から12しかなかったため、ライトバリアの負荷を克服できませんでした。おそらく将来、128コアシステムが登場し、Goがそれらを活用できるようになれば、ROCのスケーリング特性が勝利をもたらすかもしれません。そうなれば、私たちはこれに戻って再検討するかもしれませんが、今のところROCは負け戦でした。

それで、次に何をしようとしていたのでしょうか?世代別GCを試してみましょう。古いですが、良いものです。ROCはうまくいかなかったので、もっと経験のあるものに戻りましょう。

レイテンシを諦めるつもりはありませんでしたし、非移動であるという事実も諦めるつもりはありませんでした。そこで、非移動型の世代別GCが必要でした。
では、これを実現できるでしょうか?はい、できます。ただし、世代別GCではライトバリアが常にオンになります。GCサイクルが実行されているときは、現在使用しているのと同じライトバリアを使用しますが、GCがオフのときは、ポインタをバッファリングし、オーバーフロー時にバッファをカードマークテーブルにフラッシュする高速GCライトバリアを使用します。
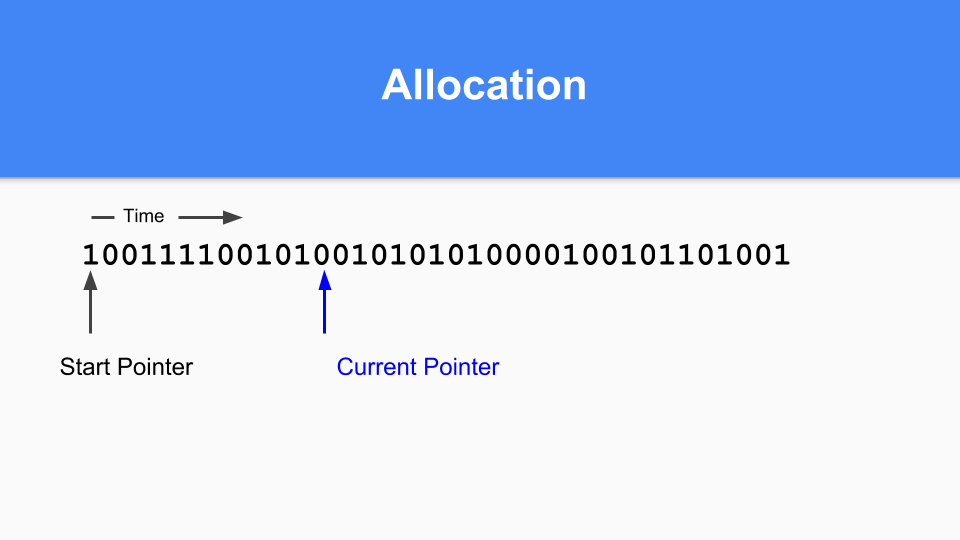
では、これは非移動型の場合にどのように機能するのでしょうか?ここにマーク/割り当てマップがあります。基本的に、現在のポインタを維持します。割り当てるときは、次のゼロを探し、そのゼロを見つけると、そのスペースにオブジェクトを割り当てます。
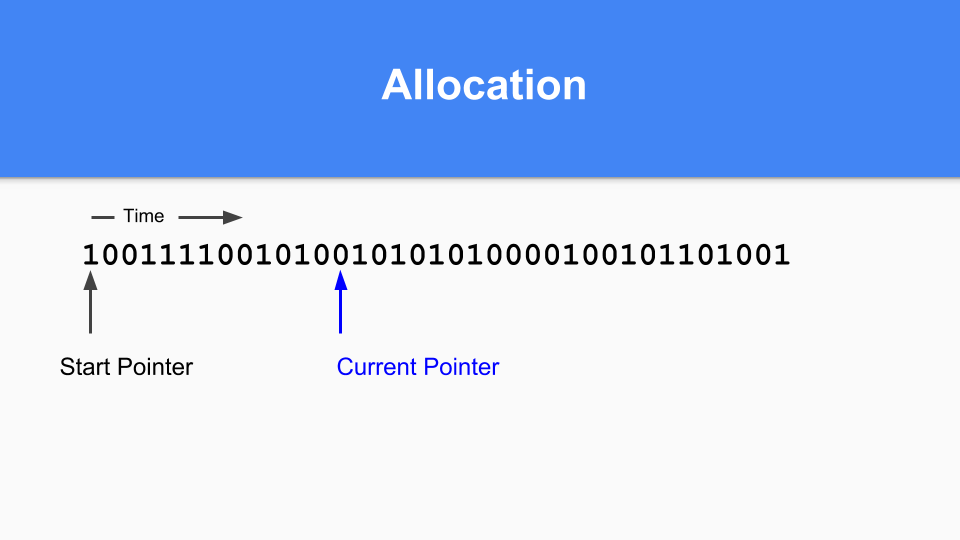
その後、現在のポインタを次の0に更新します。
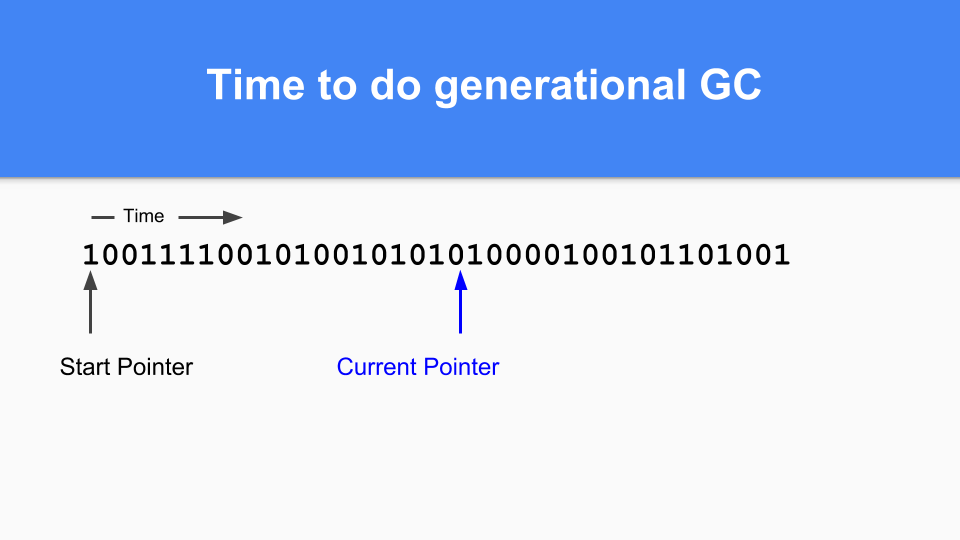
ある時点で世代別GCを行う時が来るまで続けます。マーク/割り当てベクタに1がある場合、そのオブジェクトは前回のGCで生きていたので成熟しています。それが0で、それに到達した場合、それが若いオブジェクトであることが分かります。
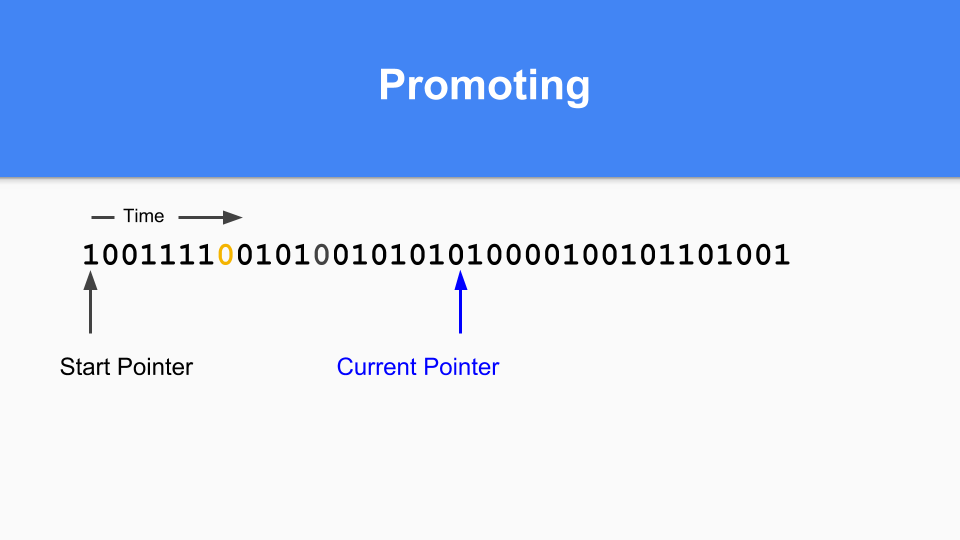
プロモーションはどのように行うのでしょうか。1とマークされたものが0とマークされたものを指している場合、そのゼロを1に設定するだけで参照オブジェクトをプロモーションします。
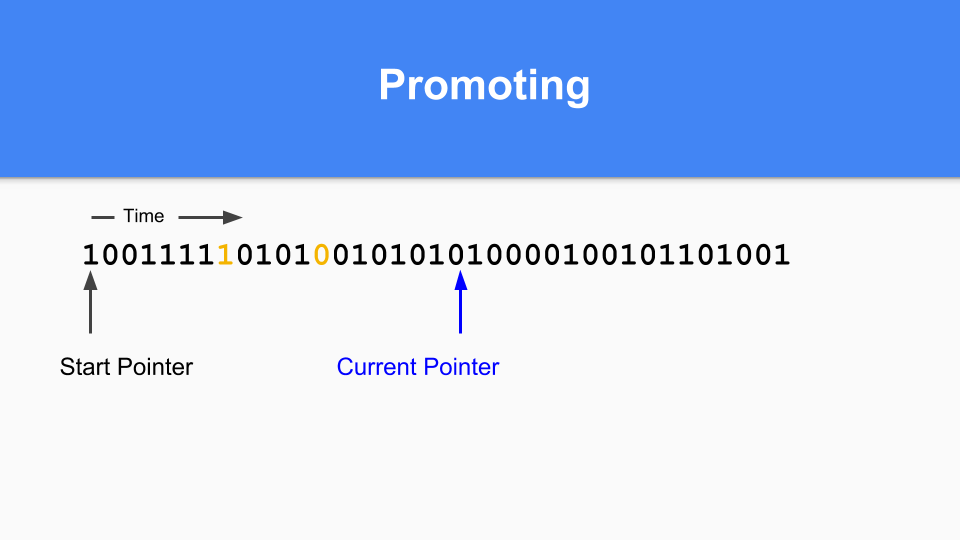
到達可能なオブジェクトがすべて昇格されるように、推移的なウォークを実行する必要があります。
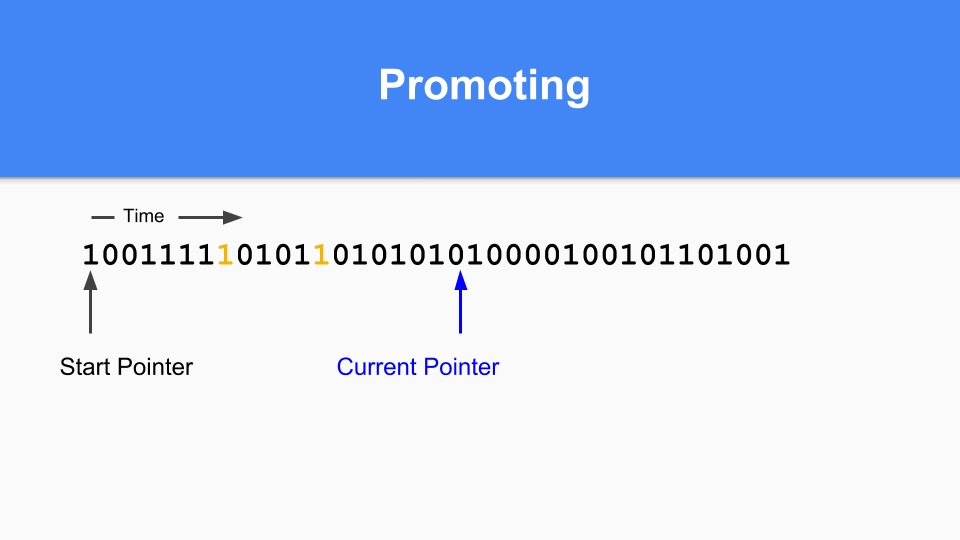
到達可能なオブジェクトがすべて昇格されると、マイナーGCは終了します。

最後に、世代別GCサイクルを終了するには、現在のポインタをベクトルの先頭に戻すだけで、継続できます。GCサイクル中に到達しなかったゼロはすべてフリーであり、再利用できます。ご存じのように、これは「スティッキービット」と呼ばれ、ハンス・ベームとその同僚によって発明されました。
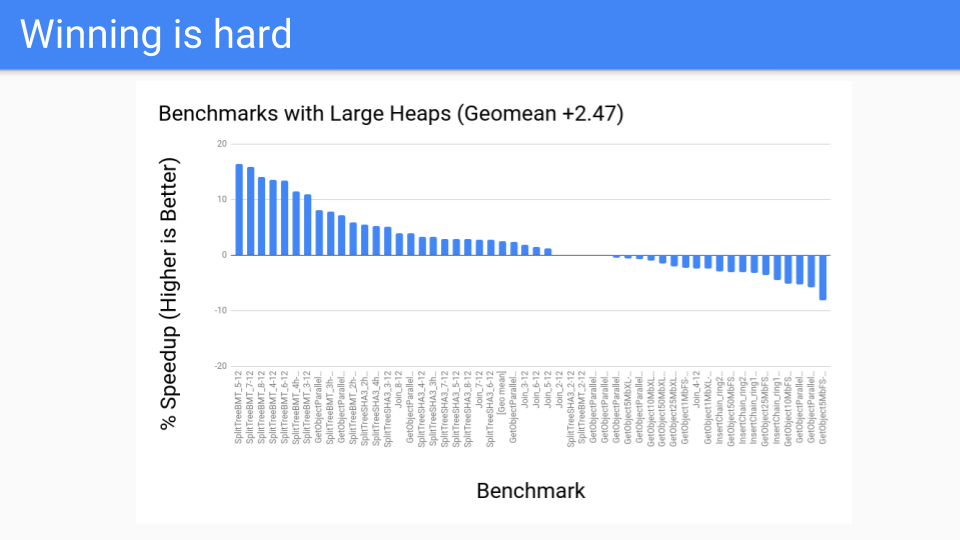
それで、パフォーマンスはどうでしたか?大規模ヒープの場合、悪くありませんでした。これらはGCがうまくいくはずのベンチマークでした。これはすべて良好でした。
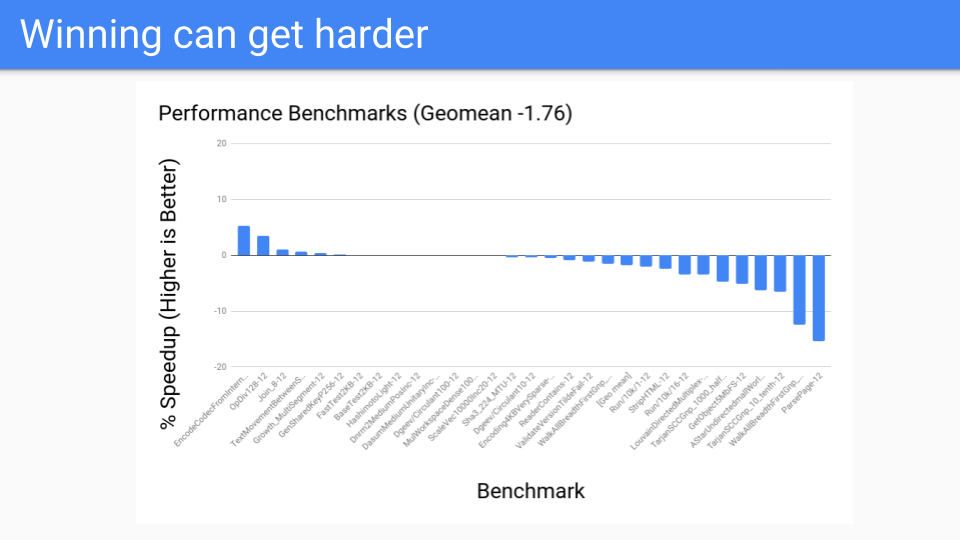
その後、パフォーマンスベンチマークで実行してみたところ、うまくいきませんでした。一体何が起こっていたのでしょうか?

ライトバリアは高速でしたが、単純に十分な速さではありませんでした。さらに、最適化が困難でした。たとえば、オブジェクトが割り当てられてから次のセーフポイントまでの間に初期化書き込みがある場合、ライトバリアの省略が可能です。しかし、すべての命令でGCセーフポイントを持つシステムに移行する必要があったため、将来的に省略できるライトバリアは実際にはありませんでした。

エスケープ解析もますます改善されていました。私たちが話していた値指向のものを覚えていますか?関数にポインタを渡す代わりに、実際の値を渡します。値を渡していたため、エスケープ解析は手続き内エスケープ解析のみを行い、手続き間解析を行う必要がありませんでした。
もちろん、ローカルオブジェクトへのポインタがエスケープした場合、オブジェクトはヒープ割り当てされます。
Goにとって世代別仮説が真実ではないわけではありません。ただ、若いオブジェクトはスタック上で若くして生まれ、若くして死ぬだけです。その結果、世代別コレクションは、他のマネージドランタイム言語で見られるほど効果的ではありません。

このように、ライトバリアに対する反発が大きくなり始めていました。今日、私たちのコンパイラは2014年当時よりもはるかに優れています。エスケープ解析は、世代別コレクタが役立つはずだった多くのオブジェクトをスタックに配置しています。私たちはユーザーがエスケープしたオブジェクトを見つけるのに役立つツールを作成し始め、些細なものであればコードを変更して、コンパイラがスタックに割り当てるのを助けることができました。
ユーザーは値指向のアプローチをより賢く採用するようになっており、ポインタの数が減少しています。配列やマップはポインタではなく値を保持しています。すべて順調です。
しかし、Goのライトバリアが今後苦戦する主要な説得力のある理由ではありません。
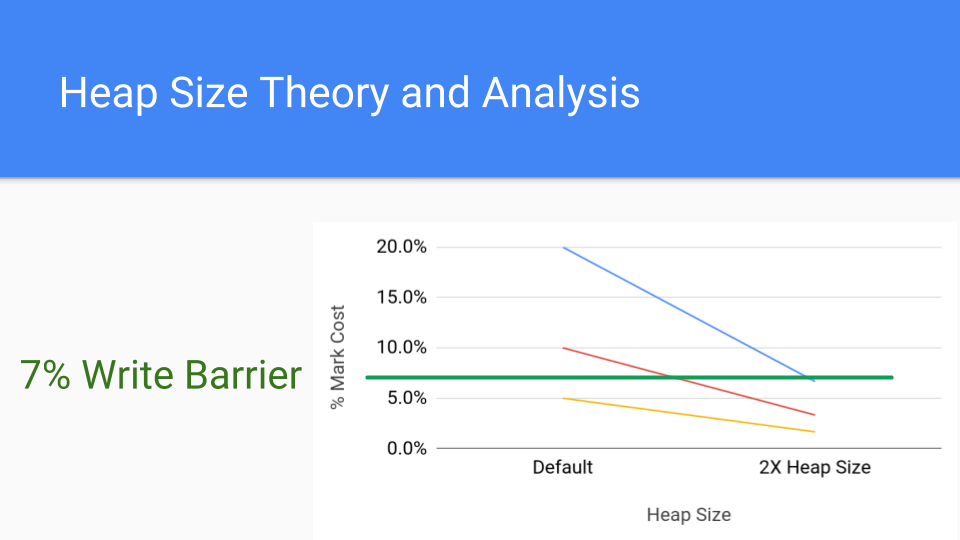
このグラフを見てください。これはマークコストの分析グラフです。各線は、マークコストを持つ可能性のある異なるアプリケーションを表しています。マークコストが20%だとしましょう。これはかなり高いですが、可能です。赤い線は10%で、これもまだ高いです。下の線は5%で、これは最近のライトバリアのコストとほぼ同じです。では、ヒープサイズを2倍にするとどうなるでしょうか?それが右側の点です。GCサイクルが頻繁でなくなるため、マークフェーズの累積コストは大幅に減少します。ライトバリアのコストは一定なので、ヒープサイズを増やすことで、マーキングコストはライトバリアのコストを下回るでしょう。
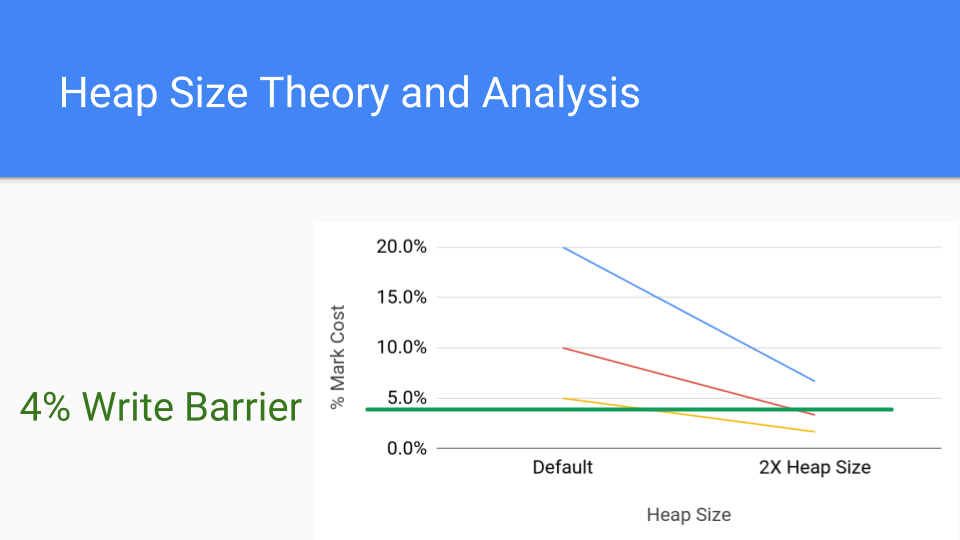
こちらはライトバリアのより一般的なコストである4%です。それでも、ヒープサイズを増やすだけで、マークバリアのコストをライトバリアのコストを下回らせることができることがわかります。
世代別GCの真の価値は、GC時間を見る際に、ライトバリアのコストが無視されることです。なぜなら、それらはミューテーター全体に散らばっているからです。これが世代別GCの大きな利点であり、フルGCサイクルの長いSTW時間を大幅に短縮しますが、必ずしもスループットを向上させるわけではありません。Goにはこのストップ・ザ・ワールドの問題がないため、スループットの問題をより詳しく検討する必要があり、それが私たちが行ったことです。

それは多くの失敗であり、そのような失敗には食べ物とランチが伴います。いつものように私は「ライトバリアがなければ、これはどれほど素晴らしいことだろう」と愚痴を言っています。
一方、オースティンはGoogleのHW GCの人々と1時間話したばかりで、彼らと話してHW GCサポートが役立つかもしれない方法を見つけるべきだと言っていました。それから私は、ゼロフィルキャッシュライン、再起動可能なアトミックシーケンス、その他私が大手ハードウェア会社で働いていたときにうまくいかなかったことについての戦場の物語を語り始めました。確かにItaniumというチップにいくつか組み込みましたが、今日のより一般的なチップには組み込むことができませんでした。したがって、この話の教訓は、単に持っているHWを使うということです。
とにかく、それがきっかけで、何かクレイジーなことを話してみましょうか?

ライトバリアなしのカードマーキングはどうでしょうか?オースティンがこのようなファイルを持っていて、彼がなぜか私に教えてくれない彼のクレイジーなアイデアをすべてこれらのファイルに書き込んでいることが判明しました。私はそれが何らかの治療的なことだと考えています。私も以前エリオットと同じことをしていました。新しいアイデアは簡単に打ち砕かれるので、世界に発表する前にそれらを保護し、強くする必要があります。まあ、とにかく彼はこのアイデアを出してきました。
そのアイデアとは、各カード内に成熟したポインタのハッシュを保持するというものです。ポインタがカードに書き込まれると、ハッシュが変更され、そのカードはマークされたと見なされます。これにより、ライトバリアのコストをハッシュのコストと交換することになります。

しかし、もっと重要なのは、ハードウェアにアラインされていることです。
今日の最新のアーキテクチャにはAES(Advanced Encryption Standard)命令があります。これらの命令の1つは暗号化グレードのハッシュを実行でき、暗号化グレードのハッシュを使用すれば、標準的な暗号化ポリシーに従う限り、衝突を心配する必要はありません。したがって、ハッシュに多くのコストはかかりませんが、ハッシュするものをロードする必要があります。幸いなことに、メモリをシーケンシャルにウォークしているので、非常に優れたメモリとキャッシュのパフォーマンスが得られます。DIMMがあり、シーケンシャルアドレスにアクセスする場合、ランダムアドレスにアクセスするよりも高速であるため、これは有利です。ハードウェアプリフェッチャが作動し、それも役立ちます。とにかく、Fortran、C、そしてSPECintベンチマークを実行するためにハードウェアを設計してきた50年、60年の歴史があります。この種のものを高速で実行するハードウェアが結果として生まれるのは驚くことではありません。
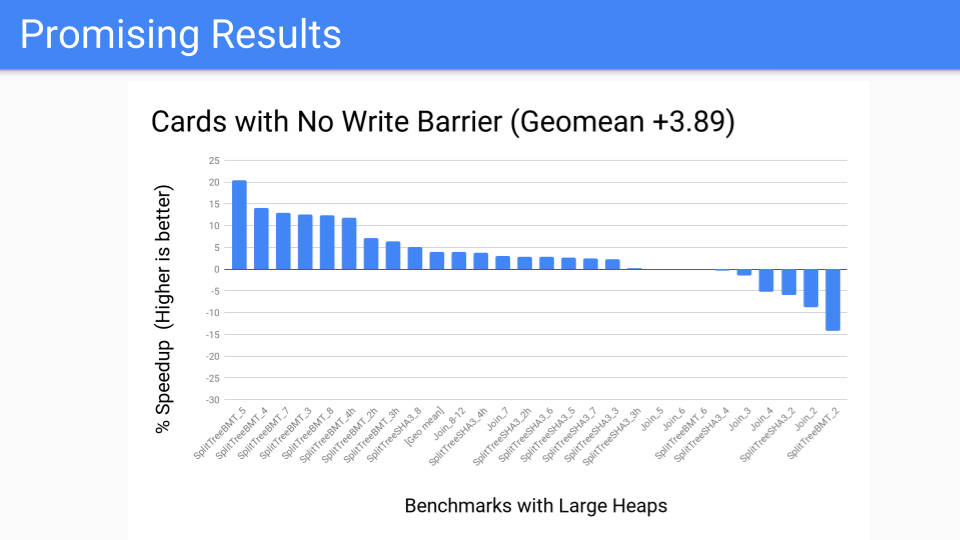
測定を行いました。これはかなり良いです。大規模ヒープ用のベンチマークスイートなので、良いはずです。
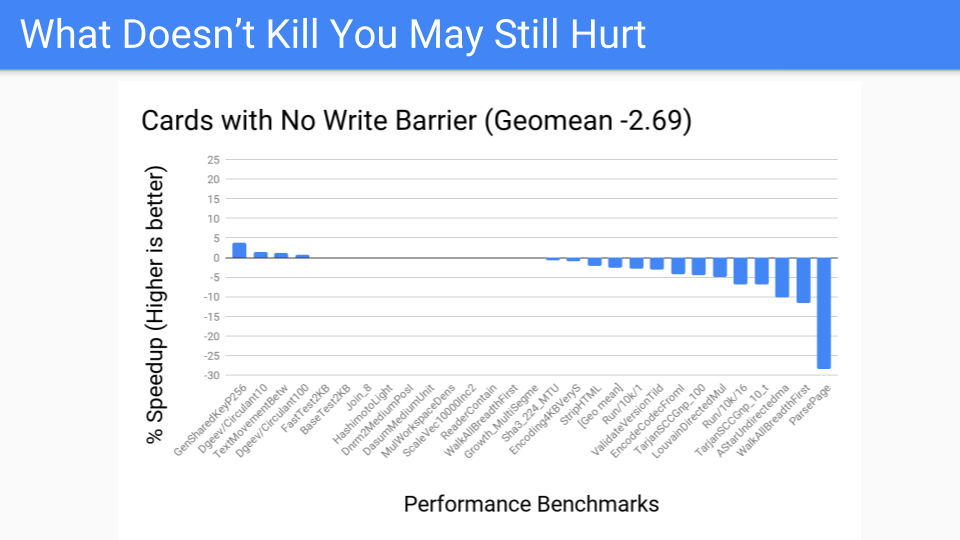
次に、パフォーマンスベンチマークではどうなるかと言いました。あまり良くない、いくつかの外れ値があります。しかし、ライトバリアをミューテーターで常にオンにするのではなく、GCサイクルの一部として実行するように変更しました。これで、世代別GCを行うかどうかの決定は、GCサイクルの開始時まで遅延されます。カードの作業を局所化したため、そこでの制御が向上しました。ツールが手元にあるので、Pacerに渡すことができ、Pacerは世代別GCの恩恵を受けないプログラムを動的に切り捨てるのに役立つでしょう。しかし、これは今後成功するのでしょうか?私たちは、今後のハードウェアがどうなるかを知るか、少なくとも考える必要があります。

未来のメモリとは?
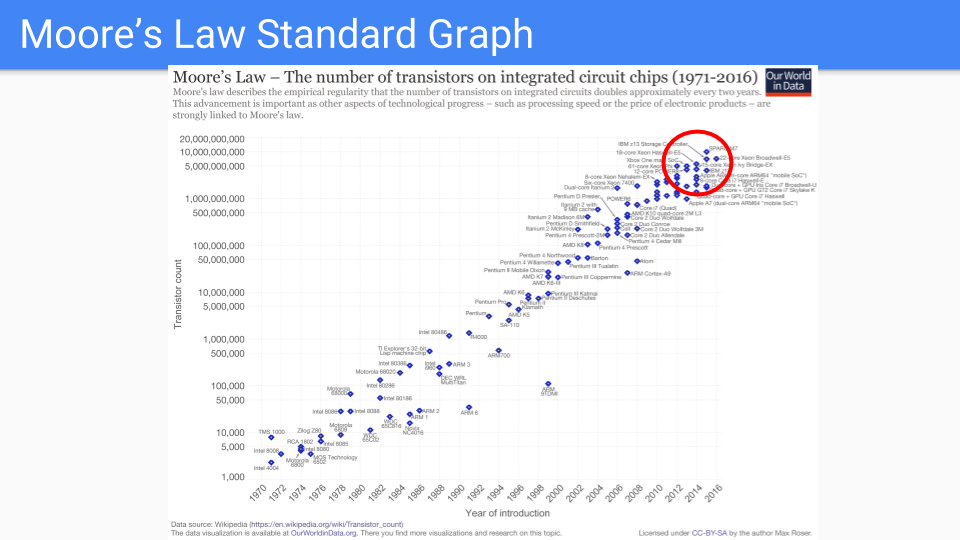
このグラフを見てみましょう。これは古典的なムーアの法則のグラフです。Y軸は単一チップ内のトランジスタ数を示す対数スケールです。X軸は1971年から2016年までの年を表しています。これらの年は、どこかの誰かがムーアの法則が死んだと予測した年であることに注目します。
デナールスケーリングは、10年ほど前に周波数改善を終わらせました。新しいプロセスは、立ち上げに時間がかかっています。そのため、2年ではなく、今は4年以上かかります。したがって、ムーアの法則の鈍化の時代に入っていることはかなり明らかです。
赤い円の中のチップだけを見てみましょう。これらはムーアの法則を維持するのに最適なチップです。
これらは、ロジックがますます単純になり、何度も複製されているチップです。多数の同一コア、複数のメモリーコントローラーとキャッシュ、GPU、TPUなどです。
単純化と複製を続けていくと、漸近的に数本のワイヤ、トランジスタ、コンデンサに行き着きます。言い換えれば、DRAMメモリセルです。
別の言い方をすれば、メモリを2倍にすることは、コアを2倍にすることよりも価値があると私たちは考えています。
元のグラフはwww.kurzweilai.net/ask-ray-the-future-of-moores-lawにあります。
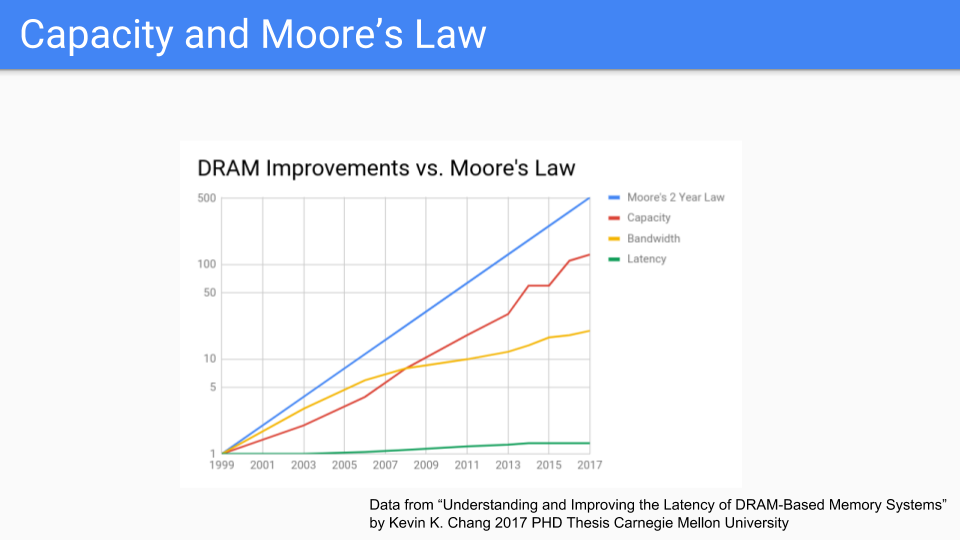
DRAMに焦点を当てた別のグラフを見てみましょう。これらはCMUの最近の博士論文からの数値です。これを見ると、ムーアの法則が青い線であることがわかります。赤い線は容量で、ムーアの法則に従っているようです。奇妙なことに、ドラムメモリを使用していた1939年にまでさかのぼるグラフを見たのですが、その容量とムーアの法則が一緒に進んでいたので、このグラフは長い間続いており、この部屋にいる誰よりも長く続いていることは確かです。
このグラフをCPUの周波数や、ムーアの法則は死んだという様々なグラフと比較すると、メモリ、少なくともチップの容量はCPUよりも長くムーアの法則に従うという結論に達します。帯域幅(黄色の線)は、メモリの周波数だけでなく、チップから得られるピンの数にも関係しているため、追いついてはいませんが、悪くもありません。
遅延(緑色の線)は非常に悪化していますが、シーケンシャルアクセスの場合の遅延はランダムアクセスの場合の遅延よりも優れていることに注意します。
(データは「Understanding and Improving the Latency of DRAM-Based Memory Systems Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Electrical and Computer Engineering Kevin K. Chang M.S., Electrical & Computer Engineering, Carnegie Mellon University B.S., Electrical & Computer Engineering, Carnegie Mellon University Carnegie Mellon University Pittsburgh, PA May, 2017」より。詳細はKevin K. Changの論文を参照してください。序文の元のグラフはムーアの法則の線を簡単に描ける形式ではなかったので、X軸をより均一に変更しました。)
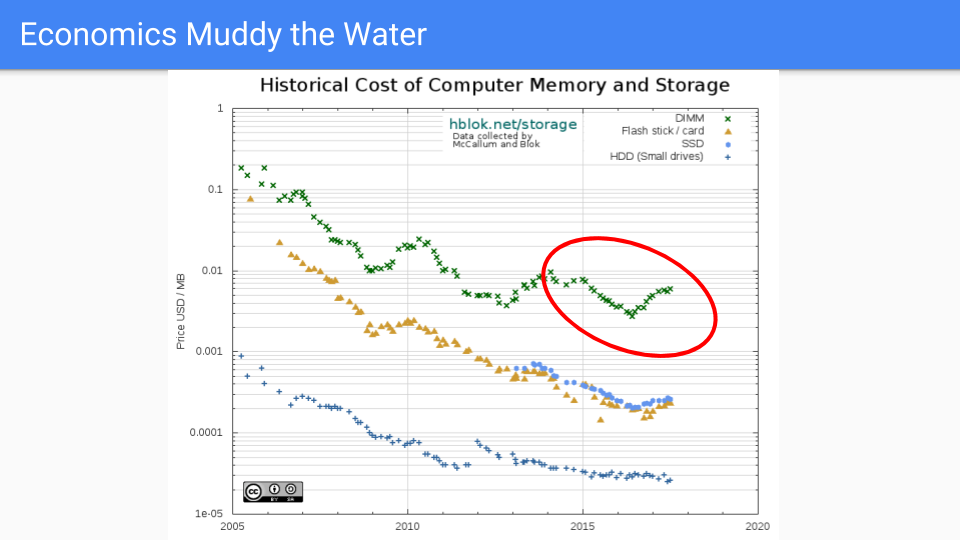
本題に入りましょう。これは実際のDRAM価格で、2005年から2016年にかけて一般的に下落しています。2005年を選んだのは、デナールスケーリングが終わり、それに伴って周波数改善も終わった時期だからです。
赤い円の中、つまりGoのGCレイテンシ削減の作業が行われていた期間を見ると、最初の数年間は価格が順調に推移していたことがわかります。最近は、需要が供給を上回り、過去2年間で価格が上昇したため、あまり良くありません。もちろん、トランジスタは大きくならず、場合によってはチップ容量が増加しているため、これは市場の力によって動かされています。RAMBUSや他のチップメーカーは、今後、2019年から2020年の間に次のプロセス縮小が見られるだろうと述べています。
メモリ業界における世界的な市場の力学については、価格が周期的であり、長期的には供給が需要を満たす傾向があること以上の推測は控えます。
長期的には、メモリ価格はCPU価格よりもはるかに速い速度で下落すると考えています。
(出典:https://hblok.net/blog/ および https://hblok.net/storage_data/storage_memory_prices_2005-2017-12.png)
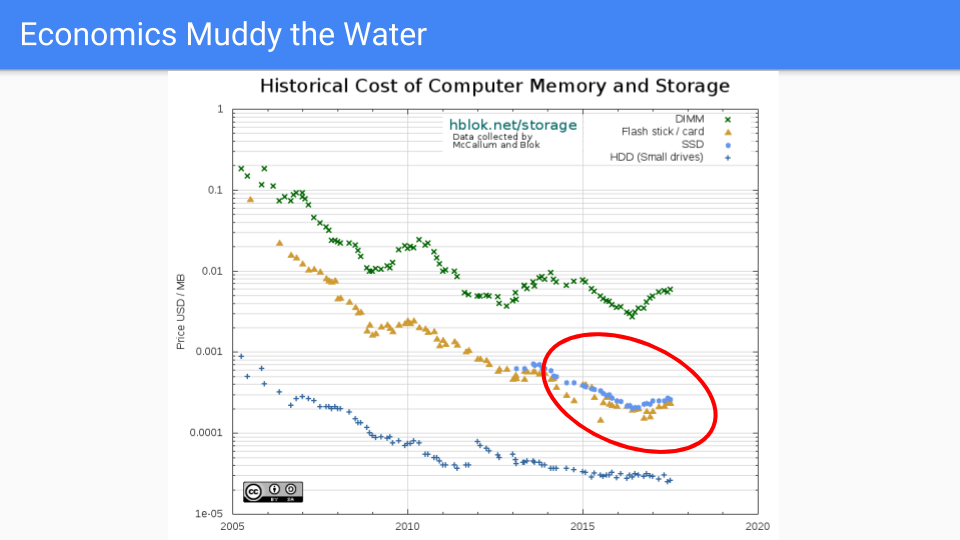
この他の線を見てみましょう。この線上にいられたらいいのに。これはSSDの線です。価格を低く保つのがうまくいっています。これらのチップの物質物理学はDRAMよりもはるかに複雑です。ロジックはより複雑で、1セルあたり1トランジスタではなく、半ダースほどのトランジスタがあります。
今後は、DRAMとSSDの間に、Intelの3D XPointや相変化メモリ(PCM)などのNVRAMが存在するようになるでしょう。今後10年間で、この種のメモリの利用可能性が高まり、主流になる可能性があり、これにより、メモリを追加することがサーバーに価値を追加する安価な方法であるという考えがさらに強化されるでしょう。
さらに重要なのは、DRAMの競合となる代替品が登場すると予想されることです。5年後や10年後にどれが好まれるかはわかりませんが、競争は激しく、ヒープメモリはここでハイライトされている青いSSDの線に近づくでしょう。
これらすべてが、常時オンのバリアを避け、メモリを増やすという私たちの決定を強化しています。

では、これらすべては今後のGoにとって何を意味するのでしょうか?

ユーザーから寄せられる特殊なケースを検討しながら、ランタイムをより柔軟で堅牢にすることを目指しています。スケジューラをより厳密にし、より優れた決定性 fairness を実現したいと考えていますが、パフォーマンスを犠牲にするつもりはありません。
また、GC APIの表面積を増やすつもりもありません。すでに約10年経ちましたが、つまみが2つあり、それが適切だと感じています。新しいフラグを追加するほど重要なアプリケーションはありません。
また、すでにかなり良いエスケープ解析を改善し、Goの値指向プログラミングを最適化する方法も検討します。プログラミングだけでなく、ユーザーに提供するツールにおいてもです。
アルゴリズム的には、特に常にオンになっているバリアの使用を最小限に抑える設計空間の領域に焦点を当てます。
最後に、そして最も重要なことですが、今後5年間、願わくば今後10年間は、CPUよりもRAMを優遇するムーアの法則の傾向に乗じることを期待しています。
以上です。ありがとうございました。

追伸 Goチームは、Goランタイムおよびコンパイラツールチェーンの開発と保守を支援するエンジニアを募集しています。
ご興味のある方は、採用情報をご覧ください。
次の記事: Go Cloudによるポータブルクラウドプログラミング
前の記事: Go行動規範の更新
ブログインデックス