The Go Blog
Go スライス: 使用法と内部構造
はじめに
Goのスライス型は、型付きデータのシーケンスを扱うための便利で効率的な手段を提供します。スライスは他の言語の配列に似ていますが、いくつかの珍しいプロパティを持っています。この記事では、スライスとは何か、そしてどのように使われるかを見ていきます。
配列
スライス型はGoの配列型の上に構築された抽象化なので、スライスを理解するためにはまず配列を理解しなければなりません。
配列型の定義は、長さと要素の型を指定します。例えば、型[4]intは4つの整数の配列を表します。配列のサイズは固定です。その長さは型の構成要素です ([4]intと[5]intは異なる互換性のない型です)。配列は通常の方法でインデックス付けでき、式s[n]は0から始まるn番目の要素にアクセスします。
var a [4]int
a[0] = 1
i := a[0]
// i == 1
配列は明示的に初期化する必要はありません。配列のゼロ値は、その要素自体がゼロ化された、すぐに使える配列です。
// a[2] == 0, the zero value of the int type
[4]intのメモリ内表現は、4つの整数値が順番に配置されているだけです。

Goの配列は値です。配列変数は配列全体を表し、配列の最初の要素へのポインタではありません (C言語の場合とは異なります)。これは、配列の値を代入したり渡したりすると、その内容がコピーされることを意味します。(コピーを避けるには、配列へのポインタを渡すことができますが、それは配列へのポインタであり、配列ではありません。)配列を考える一つの方法は、インデックス付きフィールドを持つ構造体の一種として考えることです。つまり、固定サイズの複合値です。
配列リテラルは次のように指定できます。
b := [2]string{"Penn", "Teller"}
あるいは、コンパイラに配列の要素数を数えさせることもできます。
b := [...]string{"Penn", "Teller"}
どちらの場合も、bの型は[2]stringです。
スライス
配列には役割がありますが、少し柔軟性に欠けるため、Goのコードではあまり見かけません。しかし、スライスはいたるところにあります。これらは配列を基盤として、優れた機能と利便性を提供します。
スライスの型指定は[]Tで、Tはスライスの要素の型です。配列型とは異なり、スライス型には指定された長さがありません。
スライスリテラルは配列リテラルと同じように宣言されますが、要素数を省略します。
letters := []string{"a", "b", "c", "d"}
スライスは、シグネチャを持つ組み込み関数makeで作成できます。
func make([]T, len, cap) []T
ここでTは作成するスライスの要素の型を表します。make関数は型、長さ、およびオプションの容量を受け取ります。呼び出されると、makeは配列を割り当て、その配列を参照するスライスを返します。
var s []byte
s = make([]byte, 5, 5)
// s == []byte{0, 0, 0, 0, 0}
容量引数が省略された場合、指定された長さにデフォルト設定されます。同じコードのより簡潔なバージョンを以下に示します。
s := make([]byte, 5)
スライスの長さと容量は、組み込み関数lenとcapを使って調べることができます。
len(s) == 5
cap(s) == 5
次の2つのセクションでは、長さと容量の関係について説明します。
スライスのゼロ値はnilです。len関数とcap関数はどちらもnilスライスに対して0を返します。
スライスは、既存のスライスまたは配列を「スライスする」ことによっても形成できます。スライスは、コロンで区切られた2つのインデックスを持つ半開範囲を指定することによって行われます。例えば、式b[1:4]はbの要素1から3を含むスライスを作成します(結果のスライスのインデックスは0から2になります)。
b := []byte{'g', 'o', 'l', 'a', 'n', 'g'}
// b[1:4] == []byte{'o', 'l', 'a'}, sharing the same storage as b
スライス式の開始インデックスと終了インデックスはオプションです。これらはそれぞれゼロとスライスの長さにデフォルト設定されます。
// b[:2] == []byte{'g', 'o'}
// b[2:] == []byte{'l', 'a', 'n', 'g'}
// b[:] == b
これは、配列からスライスを作成するための構文でもあります。
x := [3]string{"Лайка", "Белка", "Стрелка"}
s := x[:] // a slice referencing the storage of x
スライスの内部構造
スライスは配列セグメントの記述子です。配列へのポインタ、セグメントの長さ、およびその容量(セグメントの最大長)で構成されます。

先にmake([]byte, 5)で作成した変数sは、次のような構造になっています。
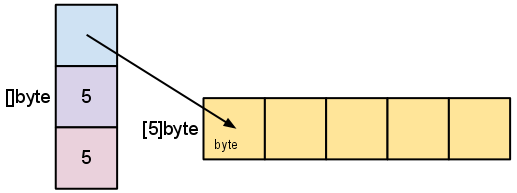
長さは、スライスが参照する要素の数です。容量は、基盤となる配列の要素の数です(スライスポインタが参照する要素から始まります)。長さと容量の違いは、次のいくつかの例を順に見ていくと明らかになります。
sをスライスすると、スライスデータ構造の変更と、それが基盤となる配列にどのように関連しているかを観察してください。
s = s[2:4]
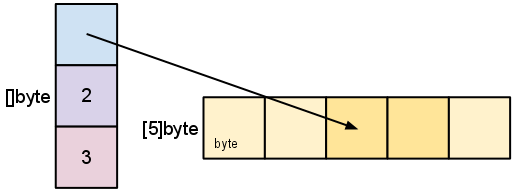
スライスはスライスのデータをコピーしません。元の配列を指す新しいスライス値を作成します。これにより、スライス操作は配列インデックスの操作と同じくらい効率的になります。したがって、リ・スライスされたスライスの要素(スライス自体ではない)を変更すると、元のスライスの要素が変更されます。
d := []byte{'r', 'o', 'a', 'd'}
e := d[2:]
// e == []byte{'a', 'd'}
e[1] = 'm'
// e == []byte{'a', 'm'}
// d == []byte{'r', 'o', 'a', 'm'}
以前、sをその容量よりも短い長さにスライスしました。もう一度スライスすることで、sをその容量まで拡張できます。
s = s[:cap(s)]
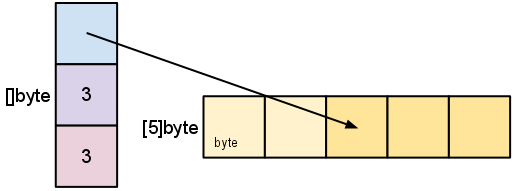
スライスは容量を超えて拡張することはできません。そうしようとすると、スライスや配列の境界外にインデックスを付けた場合と同様に、ランタイムパニックが発生します。同様に、配列内の以前の要素にアクセスするために、スライスをゼロ未満に再スライスすることはできません。
スライスの拡張(copy関数とappend関数)
スライスの容量を増やすには、新しい大きなスライスを作成し、元のスライスの内容をそれにコピーする必要があります。この手法は、他の言語の動的配列の実装が内部でどのように機能するかです。次の例では、新しいスライスtを作成し、sの内容をtにコピーし、そしてスライス値tをsに代入することで、sの容量を2倍にします。
t := make([]byte, len(s), (cap(s)+1)*2) // +1 in case cap(s) == 0
for i := range s {
t[i] = s[i]
}
s = t
この一般的な操作のループ部分は、組み込みのcopy関数によって容易になります。名前が示すように、copyはソーススライスから宛先スライスにデータをコピーします。コピーされた要素の数を返します。
func copy(dst, src []T) int
copy関数は、異なる長さのスライス間のコピーをサポートしています(要素数が少ない方までしかコピーしません)。さらに、copyは、同じ基盤となる配列を共有するソーススライスと宛先スライスを処理し、重複するスライスを正しく扱います。
copyを使用すると、上記のコードスニペットを簡略化できます。
t := make([]byte, len(s), (cap(s)+1)*2)
copy(t, s)
s = t
一般的な操作として、スライスの末尾にデータを追加する機能があります。この関数はバイト要素をバイトのスライスに追加し、必要に応じてスライスを拡張し、更新されたスライス値を返します。
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
AppendByteは次のように使うことができます。
p := []byte{2, 3, 5}
p = AppendByte(p, 7, 11, 13)
// p == []byte{2, 3, 5, 7, 11, 13}
AppendByteのような関数は、スライスが拡張される方法を完全に制御できるため便利です。プログラムの特性に応じて、より小さいチャンクまたはより大きいチャンクで割り当てたり、再割り当てのサイズに上限を設定したりすることが望ましい場合があります。
しかし、ほとんどのプログラムは完全な制御を必要としないため、Goはほとんどの目的に適した組み込みのappend関数を提供しています。そのシグネチャは次のとおりです。
func append(s []T, x ...T) []T
append関数は、スライスsの末尾に要素xを追加し、より大きな容量が必要な場合はスライスを拡張します。
a := make([]int, 1)
// a == []int{0}
a = append(a, 1, 2, 3)
// a == []int{0, 1, 2, 3}
あるスライスを別のスライスに追加するには、...を使って2番目の引数を引数リストに展開します。
a := []string{"John", "Paul"}
b := []string{"George", "Ringo", "Pete"}
a = append(a, b...) // equivalent to "append(a, b[0], b[1], b[2])"
// a == []string{"John", "Paul", "George", "Ringo", "Pete"}
スライスのゼロ値(nil)はゼロ長スライスのように機能するため、スライス変数を宣言し、ループでそれに要素を追加することができます。
// Filter returns a new slice holding only
// the elements of s that satisfy fn()
func Filter(s []int, fn func(int) bool) []int {
var p []int // == nil
for _, v := range s {
if fn(v) {
p = append(p, v)
}
}
return p
}
起こりうる「落とし穴」
前述のとおり、スライスを再スライスしても、基になる配列はコピーされません。配列全体は、参照されなくなるまでメモリに保持されます。これにより、必要なのがごく一部のデータだけであるにもかかわらず、プログラムがすべてのデータをメモリに保持してしまうことがあります。
例えば、このFindDigits関数はファイルをメモリにロードし、最初の連続する数字のグループを検索し、それを新しいスライスとして返します。
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
このコードは宣伝どおりに動作しますが、返される[]byteはファイル全体を含む配列を指しています。スライスが元の配列を参照しているため、スライスが存在する限り、ガベージコレクタは配列を解放できません。ファイルの数バイトの有用なデータが、内容全体をメモリに保持し続けてしまいます。
この問題を解決するには、興味のあるデータを返す前に新しいスライスにコピーします。
func CopyDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
この関数のより簡潔なバージョンは、appendを使用して構築できます。これは読者の演習として残します。
さらに読む
Effective Goには、スライスと配列に関する詳細な説明が含まれており、Goの言語仕様ではスライスとその関連するヘルパー関数が定義されています。
次の記事: JSONとGo
前の記事: Go: ちょうど1年前
ブログインデックス