The Go Blog
実験し、簡素化し、出荷する
はじめに
これは、先週GopherCon 2019で行った私の講演のブログ投稿版です。
私たちは皆、Go 2への道を共に歩んでいますが、その道がどこへ続くのか、あるいは時にはどの方向へ進むのかさえ、正確には誰も知りません。この投稿では、Go 2への道を実際にどのように見つけ、辿っていくかについて説明します。プロセスは次のようになります。
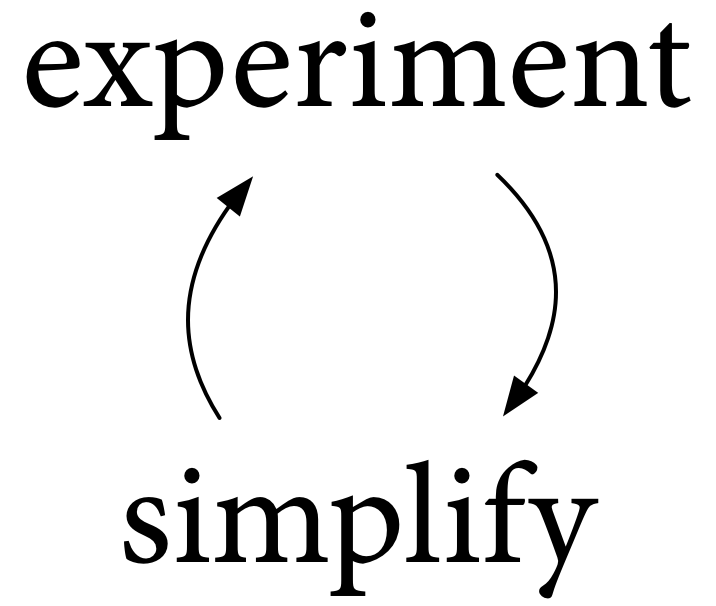
私たちは、Goが現在どのようなものであるかを実験し、よりよく理解し、何がうまく機能し、何が機能しないかを学びます。次に、可能な変更を実験し、それらをよりよく理解し、再び何がうまく機能し、何が機能しないかを学びます。これらの実験から学んだことに基づいて、簡素化します。そして、再び実験します。そして、再び簡素化します。これを繰り返します。
簡素化の4つのR
このプロセス中、Goプログラムを作成する全体的なエクスペリエンスを簡素化できる4つの主要な方法があります:再構築(reshaping)、再定義(redefining)、削除(removing)、制限(restricting)。
再構築による簡素化
簡素化の最初の方法は、既存のものを新しい形式に再構築することです。これにより、全体としてよりシンプルになります。
私たちが書くすべてのGoプログラムは、Go自体をテストするための実験として機能します。Goの初期の頃、このaddToList関数のようなコードを書くのが一般的であることをすぐに学びました。
func addToList(list []int, x int) []int {
n := len(list)
if n+1 > cap(list) {
big := make([]int, n, (n+5)*2)
copy(big, list)
list = big
}
list = list[:n+1]
list[n] = x
return list
}
バイトのスライス、文字列のスライスなど、同じコードを書きました。Goが単純すぎたため、プログラムは複雑すぎました。
そこで、プログラム内のaddToListのような多くの関数を取り、それらをGo自体が提供する1つの関数に再構築しました。appendを追加することで、Go言語は少し複雑になりましたが、全体として、appendについて学ぶコストを考慮しても、Goプログラムを作成する全体的なエクスペリエンスはよりシンプルになりました。
別の例を挙げましょう。Go 1では、Goディストリビューションにある非常に多くの開発ツールを検討し、それらを1つの新しいコマンドに再構築しました。
5a 8g
5g 8l
5l cgo
6a gobuild
6cov gofix → go
6g goinstall
6l gomake
6nm gopack
8a govet
goコマンドは今や非常に中心的であるため、それなしでどれだけ長く過ごしたか、そしてそれがどれだけ余分な作業を伴ったかを忘れがちです。
Goディストリビューションにコードと複雑さを追加しましたが、全体として、Goプログラムを作成するエクスペリエンスを簡素化しました。新しい構造は、後で見る他の興味深い実験のためのスペースも作成しました。
再定義による簡素化
簡素化の2番目の方法は、すでに持っている機能を再定義し、より多くのことができるようにすることです。再構築による簡素化と同様に、再定義による簡素化はプログラムをより簡単に書けるようにしますが、ここでは新たに学ぶことは何もありません。
たとえば、appendは元々スライスからのみ読み取るように定義されていました。バイトスライスに追記する場合、別のバイトスライスからバイトを追記することはできましたが、文字列からバイトを追記することはできませんでした。私たちは、言語に何も新しいものを追加することなく、文字列からの追記を許可するようにappendを再定義しました。
var b []byte
var more []byte
b = append(b, more...) // ok
var b []byte
var more string
b = append(b, more...) // ok later
削除による簡素化
簡素化の3番目の方法は、期待よりも有用性が低い、または重要性が低いと判明した機能を削除することです。機能を削除するということは、学ぶことが1つ減り、バグを修正することが1つ減り、気が散ったり誤用したりすることが1つ減ることを意味します。もちろん、削除はユーザーに既存のプログラムを更新することを強制し、削除を補うためにプログラムをより複雑にする可能性もあります。しかし、全体的な結果として、Goプログラムを作成するプロセスがよりシンプルになることもあります。
この例としては、非ブロック型チャネル操作のブール型形式を言語から削除したときがあります。
ok := c <- x // before Go 1, was non-blocking send
x, ok := <-c // before Go 1, was non-blocking receive
これらの操作はselectを使用しても可能だったため、どちらの形式を使用するかを決定する必要があるという混乱が生じていました。これらを削除することで、言語のパワーを損なうことなく言語を簡素化しました。
制限による簡素化
許容されるものを制限することによっても簡素化できます。Goは最初から、GoソースファイルのエンコーディングをUTF-8に制限しています。この制限により、Goソースファイルを読み取ろうとするすべてのプログラムが簡素化されます。これらのプログラムは、Latin-1、UTF-16、UTF-7、その他の形式でエンコードされたGoソースファイルを心配する必要がありません。
もう1つの重要な制限は、プログラムの書式設定におけるgofmtです。gofmtを使用して書式設定されていないGoコードを拒否するものはありませんが、Goプログラムを書き換えるツールは、それらをgofmt形式で残すという慣例を確立しています。プログラムをgofmt形式に保つと、これらの書き換えツールは書式設定の変更を行いません。変更前後を比較すると、表示される差分は実際の変更のみです。この制限はプログラムの書き換えツールを簡素化し、goimports、gorenameなどの多くの成功した実験につながりました。
Go開発プロセス
この実験と簡素化のサイクルは、過去10年間私たちが行ってきたことの良いモデルですが、問題があります。それは単純すぎます。私たちは実験と簡素化だけを行うことはできません。
結果を出荷しなければなりません。利用できるようにしなければなりません。もちろん、それを使用することで、さらに多くの実験が可能になり、さらなる簡素化が可能になり、プロセスは繰り返されます。
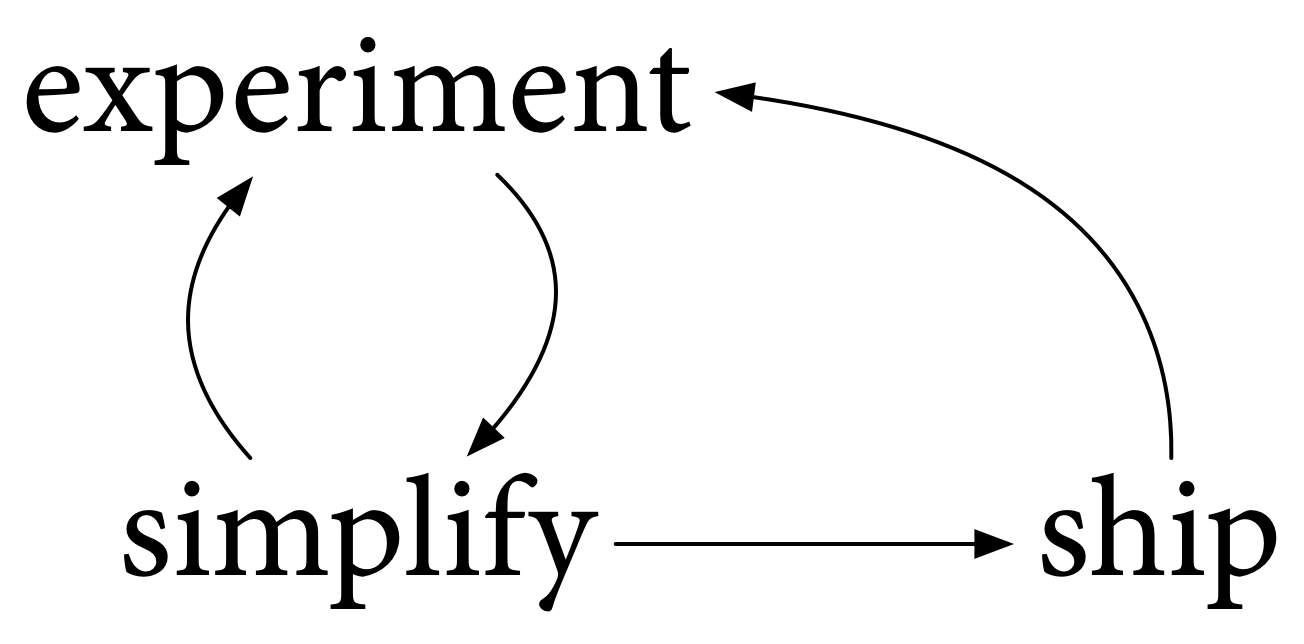
私たちは2009年11月10日にGoを初めて皆さんに出荷しました。そして、皆さんの協力を得て、2012年3月にGo 1を共に出荷しました。それ以来、12のGoリリースを出荷してきました。これらはすべて重要なマイルストーンであり、さらなる実験を可能にし、Goについてもっと学ぶのを助け、そしてもちろんGoを本番環境で利用できるようにしました。
Go 1を出荷したとき、私たちは言語の変更を伴うさらなる簡素化を試みる前に、このバージョンの言語をよりよく理解するために、Goを使用することに焦点を明確に移しました。何が機能し、何が機能しないかを真に理解するために、実験する時間が必要でした。
もちろん、Go 1以降12回のリリースがあり、私たちは引き続き実験し、簡素化し、出荷してきました。しかし、私たちは、言語の大きな変更や既存のGoプログラムを壊すことなく、Go開発を簡素化する方法に焦点を当ててきました。例えば、Go 1.5では最初の並行ガベージコレクタが出荷され、その後のリリースで改良され、一時停止時間を継続的な懸念事項から取り除くことでGo開発を簡素化しました。
2017年のGopherconで、私たちは5年間の実験を経て、Go開発を簡素化するような大幅な変更について再び考える時期が来たことを発表しました。Go 2への道は、Go 1への道とまったく同じです。Go開発全体の簡素化という目標に向かって、実験し、簡素化し、出荷するのです。
Go 2では、エラー処理、ジェネリクス、依存関係が最も重要だと考えられる具体的なトピックでした。それ以来、開発者ツールも重要なトピックであることがわかりました。
この投稿の残りの部分では、これらの各分野での私たちの取り組みがどのようにその道筋をたどるかについて説明します。途中で一度回り道をして、Go 1.13で間もなく出荷されるエラー処理の技術的な詳細を検証します。
エラー
すべての入力が有効で正しく、プログラムが依存するものが何も失敗しない場合でも、あらゆる状況で正しく機能するプログラムを作成するのは十分に困難です。そこにエラーが加わると、何が起こっても正しく機能するプログラムを作成するのはさらに困難になります。
Go 2を考える一環として、Goがその作業を簡素化できるかどうかをよりよく理解したいと考えています。
簡素化できる可能性のある側面は、エラー値とエラー構文の2つあります。約束した技術的な寄り道としてGo 1.13のエラー値の変更に焦点を当てながら、それぞれを順番に見ていきます。
エラー値
エラー値はどこからか始まったはずです。これは、osパッケージの最初のバージョンのRead関数です。
export func Read(fd int64, b *[]byte) (ret int64, errno int64) {
r, e := syscall.read(fd, &b[0], int64(len(b)));
return r, e
}
まだFile型もエラー型もありませんでした。Readおよびパッケージ内の他の関数は、基盤となるUnixシステムコールから直接errno int64を返しました。
このコードは2008年9月10日午後12時14分にチェックインされました。当時すべてがそうであったように、それは実験であり、コードは急速に変化しました。2時間5分後、APIが変更されました。
export type Error struct { s string }
func (e *Error) Print() { … } // to standard error!
func (e *Error) String() string { … }
export func Read(fd int64, b *[]byte) (ret int64, err *Error) {
r, e := syscall.read(fd, &b[0], int64(len(b)));
return r, ErrnoToError(e)
}
この新しいAPIは、最初のError型を導入しました。エラーは文字列を保持し、その文字列を返し、標準エラーに出力することができました。
ここでの意図は、整数コードを超えて一般化することでした。過去の経験から、オペレーティングシステムのエラー番号は表現が限定されすぎていること、エラーに関するすべての詳細を64ビットに詰め込む必要がないことでプログラムが簡素化されることを知っていました。エラー文字列を使用することは、過去に十分にうまくいったため、ここでも同じようにしました。この新しいAPIは7ヶ月間続きました。
翌年の4月、インターフェースの使用経験を積んだ後、さらに一般化し、os.Error型自体をインターフェースにすることで、ユーザー定義のエラー実装を許可することにしました。Printメソッドを削除することで簡素化しました。
その2年後のGo 1では、Roger Peppe氏の提案に基づき、os.Errorは組み込みのerror型となり、StringメソッドはErrorに改名されました。それ以来、何も変更されていません。しかし、私たちは多くのGoプログラムを書いてきました。その結果、エラーを実装し使用する最善の方法について多くの実験を行ってきました。
エラーは値である
errorを単純なインターフェースにし、多くの異なる実装を許可するということは、Go言語全体をエラーの定義と検査に利用できることを意味します。私たちはエラーは値であるとよく言います。他のGoの値と同じです。
例を挙げます。Unixでは、ネットワーク接続をダイヤルしようとすると、connectシステムコールが使用されます。このシステムコールはsyscall.Errnoを返します。これは、システムコールエラー番号を表し、errorインターフェースを実装する名前付き整数型です。
package syscall
type Errno int64
func (e Errno) Error() string { ... }
const ECONNREFUSED = Errno(61)
... err == ECONNREFUSED ...
syscallパッケージは、ホストオペレーティングシステムの定義されたエラー番号に対する名前付き定数も定義しています。この場合、このシステムではECONNREFUSEDは番号61です。関数からエラーを受け取るコードは、通常の値等価性を使用して、エラーがECONNREFUSEDであるかどうかをテストできます。
1レベル上がって、osパッケージでは、システムコールの失敗はすべて、エラーに加えて試行された操作を記録するより大きなエラー構造を使用して報告されます。これらの構造はいくつかあります。このSyscallErrorは、追加情報が記録されていない特定のシステムコールを呼び出す際のエラーを記述します。
package os
type SyscallError struct {
Syscall string
Err error
}
func (e *SyscallError) Error() string {
return e.Syscall + ": " + e.Err.Error()
}
さらに1レベル上がって、netパッケージでは、ネットワークの障害はすべて、ダイヤルやリスン、関連するネットワークとアドレスなど、周囲のネットワーク操作の詳細を記録するさらに大きなエラー構造を使用して報告されます。
package net
type OpError struct {
Op string
Net string
Source Addr
Addr Addr
Err error
}
func (e *OpError) Error() string { ... }
これらをまとめると、net.Dialなどの操作が返すエラーは文字列としてフォーマットできますが、構造化されたGoデータ値でもあります。この場合、エラーはnet.OpErrorであり、os.SyscallErrorにコンテキストを追加し、syscall.Errnoにコンテキストを追加します。
c, err := net.Dial("tcp", "localhost:50001")
// "dial tcp [::1]:50001: connect: connection refused"
err is &net.OpError{
Op: "dial",
Net: "tcp",
Addr: &net.TCPAddr{IP: ParseIP("::1"), Port: 50001},
Err: &os.SyscallError{
Syscall: "connect",
Err: syscall.Errno(61), // == ECONNREFUSED
},
}
エラーが値であると言うとき、Go言語全体がそれらを定義するために利用できること、そしてGo言語全体がそれらを検査するために利用できることの両方を意味します。
これはnetパッケージの例です。ソケット接続を試みるとき、ほとんどの場合、接続されるか、接続拒否されますが、時折、理由もなく誤ったEADDRNOTAVAILが発生することがあります。Goは再試行することで、この失敗モードからユーザープログラムを保護します。これを行うには、エラー構造を検査して、奥深くにあるsyscall.ErrnoがEADDRNOTAVAILであるかどうかを調べる必要があります。
コードは以下の通りです。
func spuriousENOTAVAIL(err error) bool {
if op, ok := err.(*OpError); ok {
err = op.Err
}
if sys, ok := err.(*os.SyscallError); ok {
err = sys.Err
}
return err == syscall.EADDRNOTAVAIL
}
型アサーションは、net.OpErrorラッピングを剥がします。次に、2番目の型アサーションは、os.SyscallErrorラッピングを剥がします。そして、関数はアンラップされたエラーがEADDRNOTAVAILと等しいかどうかをチェックします。
Goのエラーに関する長年の経験から学んだことは、errorインターフェースの任意の実装を定義できること、Go言語全体をエラーの構築と分解の両方に利用できること、そして単一の実装の使用を要求しないことが非常に強力であるということです。
これらのプロパティ、つまりエラーは値であること、そして必須のエラー実装が1つではないことは、維持すべき重要な点です。
1つのエラー実装を義務付けなかったことで、誰もがエラーが提供する可能性のある追加機能について実験できるようになり、github.com/pkg/errors、gopkg.in/errgo.v2、github.com/hashicorp/errwrap、upspin.io/errors、github.com/spacemonkeygo/errorsなど、多くのパッケージが生まれました。
しかし、無制限の実験には1つの問題があります。クライアントとして、遭遇する可能性のあるすべての実装の結合に対してプログラミングしなければならないことです。Go 2のために検討する価値があると思われた簡素化は、合意されたオプションのインターフェースの形で、一般的に追加される機能の標準バージョンを定義することでした。これにより、異なる実装が相互運用できるようになります。
アンラップ
これらのパッケージで最も一般的に追加される機能は、エラーからコンテキストを削除し、内部のエラーを返すことができるメソッドです。パッケージはこの操作に異なる名前と意味を使用し、コンテキストのレベルを1つ削除することもあれば、可能な限り多くのレベルを削除することもあります。
Go 1.13では、内部エラーに削除可能なコンテキストを追加するエラー実装は、内部エラーを返すUnwrapメソッドを実装し、コンテキストをアンラップするという慣例を導入しました。呼び出し元に公開するのに適切な内部エラーがない場合、エラーはUnwrapメソッドを持つべきではないか、Unwrapメソッドはnilを返す必要があります。
// Go 1.13 optional method for error implementations.
interface {
// Unwrap removes one layer of context,
// returning the inner error if any, or else nil.
Unwrap() error
}
このオプションのメソッドを呼び出すには、ヘルパー関数errors.Unwrapを呼び出します。これは、エラー自体がnilである場合や、Unwrapメソッドをまったく持たない場合などのケースを処理します。
package errors
// Unwrap returns the result of calling
// the Unwrap method on err,
// if err’s type defines an Unwrap method.
// Otherwise, Unwrap returns nil.
func Unwrap(err error) error
Unwrapメソッドを使用して、spuriousENOTAVAILのよりシンプルで汎用的なバージョンを記述できます。net.OpErrorやos.SyscallErrorのような特定のエラーラッパー実装を探す代わりに、汎用バージョンはループし、Unwrapを呼び出してコンテキストを削除し、EADDRNOTAVAILに到達するか、残りのエラーがなくなるまで続けます。
func spuriousENOTAVAIL(err error) bool {
for err != nil {
if err == syscall.EADDRNOTAVAIL {
return true
}
err = errors.Unwrap(err)
}
return false
}
しかし、このループは非常に一般的であるため、Go 1.13では、特定ターゲットを探すためにエラーを繰り返しアンラップする2番目の関数errors.Isを定義しています。そのため、ループ全体をerrors.Isへの1回の呼び出しに置き換えることができます。
func spuriousENOTAVAIL(err error) bool {
return errors.Is(err, syscall.EADDRNOTAVAIL)
}
この時点では、おそらく関数を定義することさえしないでしょう。呼び出し元で直接errors.Isを呼び出す方が、同様に明確で、よりシンプルです。
Go 1.13では、特定の型の実装が見つかるまでアンラップするerrors.As関数も導入されています。
任意にラップされたエラーで動作するコードを記述したい場合、errors.Isはエラー等価性チェックのラッパー対応バージョンです。
err == target
→
errors.Is(err, target)
そして、errors.Asはエラー型アサーションのラッパー対応バージョンです。
target, ok := err.(*Type)
if ok {
...
}
→
var target *Type
if errors.As(err, &target) {
...
}
アンラップするか、しないか?
エラーをアンラップできるようにするかどうかはAPIの決定であり、構造体フィールドをエクスポートするかどうかはAPIの決定であるのと同じです。場合によっては、その詳細を呼び出し元のコードに公開するのが適切であり、そうでない場合もあります。適切な場合はUnwrapを実装し、そうでない場合はUnwrapを実装しません。
これまで、fmt.Errorfは%vでフォーマットされた基となるエラーを呼び出し元の検査に公開していませんでした。つまり、fmt.Errorfの結果をアンラップすることはできませんでした。この例を考えてみましょう。
// errors.Unwrap(err2) == nil
// err1 is not available (same as earlier Go versions)
err2 := fmt.Errorf("connect: %v", err1)
もしerr2が呼び出し元に返された場合、その呼び出し元はerr2を開いてerr1にアクセスする方法をこれまで持っていませんでした。私たちはGo 1.13でそのプロパティを保持しました。
fmt.Errorfの結果をアンラップできるようにしたい場合は、新しい出力動詞%wも追加しました。これは%vのようにフォーマットされ、エラー値引数を必要とし、結果のエラーのUnwrapメソッドがその引数を返すようにします。例では、%vを%wに置き換えてみましょう。
// errors.Unwrap(err4) == err3
// (%w is new in Go 1.13)
err4 := fmt.Errorf("connect: %w", err3)
これで、err4が呼び出し元に返された場合、呼び出し元はUnwrapを使用してerr3を取得できます。
「常に%vを使用する(または決してUnwrapを実装しない)」や「常に%wを使用する(または常にUnwrapを実装する)」といった絶対的なルールは、「構造体フィールドをエクスポートしない」や「常に構造体フィールドをエクスポートする」といった絶対的なルールと同様に間違いであることに注意することが重要です。代わりに、正しい決定は、呼び出し元が%wの使用またはUnwrapの実装によって公開される追加情報を検査し、それに依存できるかどうかによって異なります。
この点の例として、標準ライブラリ内のすべてのエラーラッピング型で、すでにエクスポートされたErrフィールドを持っていたものは、そのフィールドを返すUnwrapメソッドも持つようになりましたが、エクスポートされていないエラーフィールドを持つ実装はそうではなく、既存のfmt.Errorfの%vの使用は依然として%vを使用し、%wは使用していません。
エラー値の出力(破棄済み)
Unwrapのデザインドラフトと共に、スタックフレーム情報やローカライズされた翻訳済みエラーのサポートを含む、よりリッチなエラー出力のためのオプションメソッドのデザインドラフトも公開しました。
// Optional method for error implementations
type Formatter interface {
Format(p Printer) (next error)
}
// Interface passed to Format
type Printer interface {
Print(args ...interface{})
Printf(format string, args ...interface{})
Detail() bool
}
これはUnwrapほど単純ではなく、ここでは詳細には触れません。冬の間、Goコミュニティと設計について議論する中で、設計が十分に単純ではないことを学びました。個々のエラー型で実装するには難しすぎ、既存のプログラムを十分に助けるものではありませんでした。総合的に見て、Go開発を簡素化するものではありませんでした。
このコミュニティの議論の結果、私たちはこの印刷設計を放棄しました。
エラー構文
それはエラー値でした。次に、エラー構文、別の放棄された実験について簡単に見ていきましょう。
これは、標準ライブラリのcompress/lzw/writer.goからのコードです。
// Write the savedCode if valid.
if e.savedCode != invalidCode {
if err := e.write(e, e.savedCode); err != nil {
return err
}
if err := e.incHi(); err != nil && err != errOutOfCodes {
return err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
if err := e.write(e, eof); err != nil {
return err
}
一見すると、このコードの半分はエラーチェックに関するものです。それを読むと目がかすみます。そして、書くのが面倒で読むのが面倒なコードは誤読しやすく、見つけにくいバグの温床になりやすいことを私たちは知っています。例えば、これら3つのエラーチェックのうちの1つは他とは異なり、素早く目を通すと見落としがちな事実です。このコードをデバッグしていた場合、それに気づくのにどれくらいの時間がかかったでしょうか?
昨年のGopherconで、キーワードcheckでマークされた新しい制御フロー構造のドラフトデザインを発表しました。Checkは関数呼び出しまたは式からのエラー結果を消費します。エラーが非nilの場合、checkはそのエラーを返します。そうでない場合、checkは呼び出しからの他の結果に評価されます。checkを使用してlzwコードを簡素化できます。
// Write the savedCode if valid.
if e.savedCode != invalidCode {
check e.write(e, e.savedCode)
if err := e.incHi(); err != errOutOfCodes {
check err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
check e.write(e, eof)
このバージョンの同じコードはcheckを使用しており、4行のコードを削除し、さらに重要なことに、e.incHiへの呼び出しがerrOutOfCodesを返すことが許可されていることを強調しています。
おそらく最も重要なことは、この設計は、後でチェックが失敗した場合に実行されるエラーハンドラブロックを定義することも可能にしたことです。これにより、このスニペットのように、共有コンテキスト追加コードを一度だけ記述できるようになります。
handle err {
err = fmt.Errorf("closing writer: %w", err)
}
// Write the savedCode if valid.
if e.savedCode != invalidCode {
check e.write(e, e.savedCode)
if err := e.incHi(); err != errOutOfCodes {
check err
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
check e.write(e, eof)
本質的に、checkはifステートメントを短縮したものであり、handleはdeferに似ていますが、エラーの戻りパス専用でした。他の言語の例外とは対照的に、この設計は、すべての潜在的な失敗呼び出しがコードに明示的にマークされるというGoの重要な特性を維持しました。現在はif err != nilの代わりにcheckキーワードを使用しています。
この設計の大きな問題は、handleがdeferとあまりにも多く、かつ紛らわしい方法で重複していたことです。
5月に、私たちは3つの簡素化を伴う新しいデザインを投稿しました。deferとの混乱を避けるため、デザインはhandleを捨ててdeferのみを使用することにしました。RustやSwiftの同様のアイデアと合わせるため、デザインはcheckをtryに改名しました。そして、gofmtのような既存のパーサーが認識する方法で実験を可能にするため、check(現在のtry)をキーワードから組み込み関数に変更しました。
これで同じコードはこのようになります。
defer errd.Wrapf(&err, "closing writer")
// Write the savedCode if valid.
if e.savedCode != invalidCode {
try(e.write(e, e.savedCode))
if err := e.incHi(); err != errOutOfCodes {
try(err)
}
}
// Write the eof code.
eof := uint32(1)<<e.litWidth + 1
try(e.write(e, eof))
6月のほとんどの期間、この提案についてGitHubで公開討論を行いました。
checkまたはtryの基本的な考え方は、各エラーチェックで繰り返される構文の量を短縮し、特にreturnステートメントを見えないようにすることで、エラーチェックを明示的に保ち、興味深いバリエーションをよりよく強調することでした。しかし、公開フィードバックの議論中に提起された興味深い点の1つは、明示的なifステートメントとreturnがないと、デバッグ用のprintを配置する場所がなく、ブレークポイントを配置する場所がなく、コードカバレッジの結果で未実行として表示されるコードがないということでした。私たちが追い求めていた利点は、これらの状況をより複雑にするという代償を伴いました。全体的に見て、この点や他の考慮事項から、全体的な結果がよりシンプルなGo開発になるかどうかは全く明らかではなかったため、この実験は中止しました。
それがエラー処理に関するすべてです。今年主要な焦点の1つでした。
ジェネリクス
さて、次は少し議論の余地が少ないもの、ジェネリクスです。
Go 2で特定した2番目の大きなトピックは、型パラメーターを持つコードを記述する何らかの方法でした。これにより、汎用的なデータ構造や、あらゆる種類のスライス、チャネル、マップで動作する汎用的な関数を記述できるようになります。たとえば、ここに汎用チャネルフィルターがあります。
// Filter copies values from c to the returned channel,
// passing along only those values satisfying f.
func Filter(type value)(f func(value) bool, c <-chan value) <-chan value {
out := make(chan value)
go func() {
for v := range c {
if f(v) {
out <- v
}
}
close(out)
}()
return out
}
Goの作業が始まって以来、ジェネリクスについて考えており、2010年には最初の具体的な設計を書き、却下しました。2013年末までにさらに3つの設計を書き、却下しました。4つの放棄された実験ですが、失敗した実験ではありません。checkやtryから学んだように、それらから学びました。毎回、Go 2への道は正確にはその方向ではないことを学び、探求する価値のある他の方向性に気づきました。しかし、2013年までに、他の懸念事項に焦点を当てる必要があると判断し、このトピック全体を数年間棚上げしました。
昨年、私たちは再び探求と実験を始め、昨年の夏、Gopherconでコントラクトのアイデアに基づく新しいデザインを発表しました。私たちは実験と簡素化を続け、デザインをよりよく理解するためにプログラミング言語理論の専門家と協力してきました。
全体として、私たちはGo開発を簡素化するような良い方向に向かっていると期待しています。それでも、この設計も機能しないことがわかるかもしれません。この実験を放棄し、学んだことに基づいて道を調整する必要があるかもしれません。結果がわかるでしょう。
Gophercon 2019で、イアン・ランス・テイラーは、Goにジェネリクスを追加したい理由と、最新の設計ドラフトを簡単に紹介しました。詳細については、彼のブログ投稿「Why Generics?」をご覧ください。
依存関係
Go 2で特定された3番目の大きなトピックは、依存関係管理でした。
2010年に、goinstallというツールを公開しました。これを「パッケージインストールの実験」と呼びました。これは依存関係をダウンロードし、GoディストリビューションツリーのGOROOTに保存しました。
goinstallで実験する中で、Goディストリビューションとインストールされたパッケージは分離しておくべきであることがわかりました。そうすれば、すべてのGoパッケージを失うことなく新しいGoディストリビューションに変更できます。そこで2011年に、メインのGoディストリビューションに見つからないパッケージをどこで探すかを指定する環境変数GOPATHを導入しました。
GOPATHを追加することで、Goパッケージの場所が増えましたが、GoディストリビューションとGoライブラリを分離することで、Go開発全体が簡素化されました。
互換性
goinstallの実験は意図的にパッケージのバージョン管理という明確な概念を省いていました。代わりに、goinstallは常に最新のコピーをダウンロードしました。これは、パッケージインストールに関する他の設計問題に集中できるようにするためでした。
GoinstallはGo 1の一部としてgo getになりました。バージョンについて尋ねられたとき、私たちは追加ツールを作成して実験することを奨励し、彼らはそうしました。そして、パッケージ作者には、Go 1ライブラリに対して行ったのと同じ下位互換性をユーザーに提供するよう奨励しました。Go FAQからの引用です。
「公開用のパッケージは、進化するにつれて後方互換性を維持するよう努めるべきです。
異なる機能が必要な場合は、古いものを変更するのではなく、新しい名前を追加してください。
完全な変更が必要な場合は、新しいインポートパスを持つ新しいパッケージを作成してください。」
この慣例は、作者が実行できることを制限することで、パッケージを使用する全体的なエクスペリエンスを簡素化します。APIへの破壊的な変更を避け、新しい機能には新しい名前を付け、全く新しいパッケージデザインには新しいインポートパスを与えます。
もちろん、人々は実験を続けました。最も興味深い実験の1つは、Gustavo Niemeyerによって開始されました。彼はgopkg.inというGitリダイレクタを作成しました。これは、異なるAPIバージョンに対して異なるインポートパスを提供することで、パッケージ作者が新しいパッケージデザインに新しいインポートパスを与えるという慣例に従うのを助けました。
例えば、GitHubリポジトリgo-yaml/yamlのGoソースコードには、v1とv2のセマンティックバージョンタグで異なるAPIがあります。gopkg.inサーバーは、これらを異なるインポートパスgopkg.in/yaml.v1とgopkg.in/yaml.v2で提供しています。
新しいバージョンのパッケージが古いバージョンの代わりに使用できるような後方互換性を提供するという慣例は、go getの非常に単純なルール「常に最新のコピーをダウンロードする」が今日でもうまく機能する理由です。
バージョン管理とベンダーリング
しかし、本番環境では、ビルドの再現性を確保するために、依存関係のバージョンについてより正確である必要があります。
Keith Rarickのgoven (2012) やgodep (2013)、Matt Butcherのglide (2014)、Dave Cheneyのgb (2015) など、多くの人々がそのためのツールを作成し、ニーズに合わせて実験しました。これらのツールはすべて、依存関係パッケージを自分のソース管理リポジトリにコピーするというモデルを使用しています。これらのパッケージをインポート可能にするための正確なメカニズムは様々でしたが、どれも必要以上に複雑に見えました。
コミュニティ全体での議論の後、Keith Rarickによる提案を採用し、GOPATHのトリックなしにコピーされた依存関係を参照する明示的なサポートを追加しました。これは再構築による簡素化でした。addToListとappendと同様に、これらのツールはすでにその概念を実装していましたが、必要以上に不器用でした。ベンダーディレクトリの明示的なサポートを追加することで、これらの使用全体が簡素化されました。
goコマンドでベンダーディレクトリを出荷したことで、ベンダーリング自体に関するさらなる実験が行われ、いくつかの問題があることに気づきました。最も深刻な問題は、*パッケージの一意性*が失われたことでした。以前は、特定のビルド中、インポートパスが多くの異なるパッケージに現れることがあり、すべてのインポートは同じターゲットを参照していました。しかし、ベンダーリングでは、異なるパッケージ内の同じインポートパスが、パッケージの異なるベンダーコピーを参照する可能性があり、それらのすべてが最終的な結果バイナリに現れることになります。
当時、この特性に名前はありませんでした。パッケージの一意性。それはGOPATHモデルがどのように機能するかというだけでした。それがなくなるまで、私たちはそれを完全に認識していませんでした。
ここには、checkとtryのエラー構文提案と並行する点があります。その場合、私たちは目に見えるreturnステートメントが、それを削除することを検討するまで気づかなかった方法で機能することに依存していました。
ベンダーディレクトリのサポートを追加したとき、依存関係を管理するためのツールが多数存在していました。ベンダーディレクトリとベンダーリングメタデータのフォーマットに関する明確な合意があれば、Goプログラムがテキストファイルに保存される方法に関する合意が、Goコンパイラ、テキストエディタ、およびgoimportsやgorenameのようなツールの相互運用を可能にするのと同じように、さまざまなツールが相互運用できるようになると考えました。
これは、ナイーブな楽観主義であることが判明しました。ベンダーリングツールはすべて微妙な意味合いで異なっていました。相互運用には、セマンティクスについてすべてのツールが合意するように変更する必要があり、それぞれのユーザーを壊す可能性がありました。収束は起こりませんでした。
Dep
Gophercon 2016で、私たちは依存関係を管理するための単一のツールを定義する取り組みを開始しました。その取り組みの一環として、さまざまな種類のユーザーを対象にアンケート調査を実施し、依存関係管理に関して彼らが何を必要としているかを理解しました。そして、新しいツール、後にdepとなるツールの開発チームが作業を開始しました。
Depは既存のすべての依存関係管理ツールを置き換えることを目指していました。目標は、既存の異なるツールを単一のツールに再構築することで簡素化することでした。それは部分的に達成されました。Depはまた、プロジェクトツリーの最上位に1つのベンダーディレクトリを持つことで、ユーザーのパッケージの一意性を回復しました。
しかし、depはまた、私たちが完全に理解するのに時間がかかった深刻な問題を引き起こしました。問題は、depがglideのデザイン選択を採用し、インポートパスを変更せずに特定のパッケージに対する互換性のない変更をサポートし、奨励したことでした。
例を挙げます。独自のプログラムを構築しているとします。設定ファイルが必要なので、人気のGo YAMLパッケージのバージョン2を使用します。
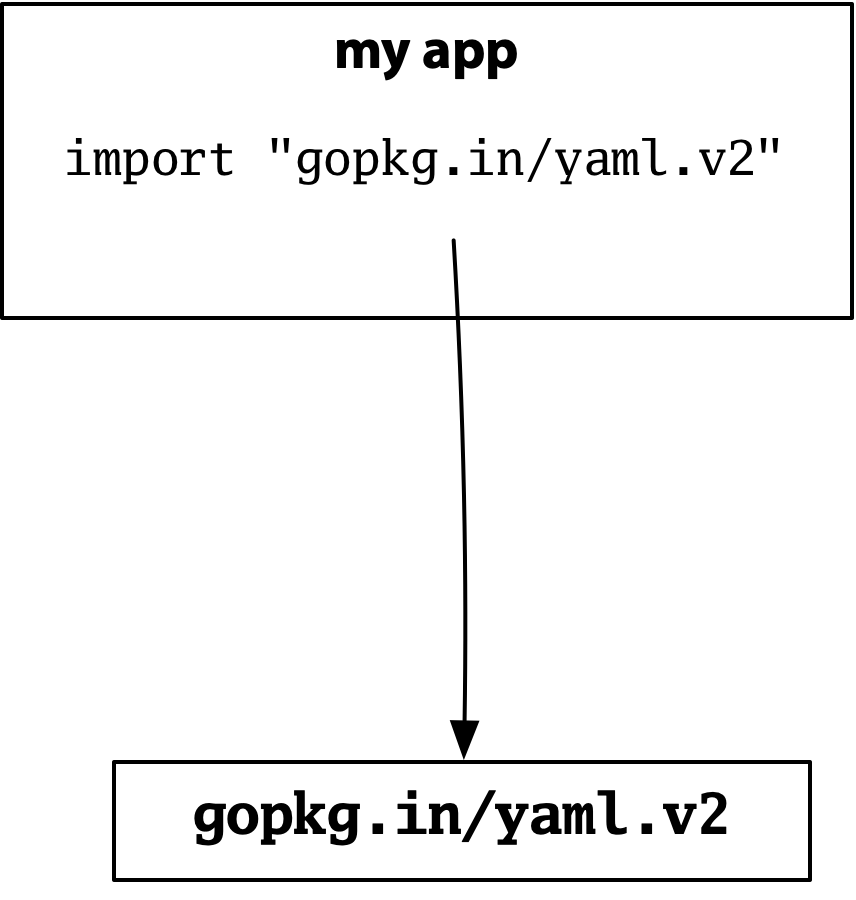
次に、プログラムがKubernetesクライアントをインポートしていると仮定します。KubernetesはYAMLを extensively 使用しており、同じ人気パッケージのバージョン1を使用しています。
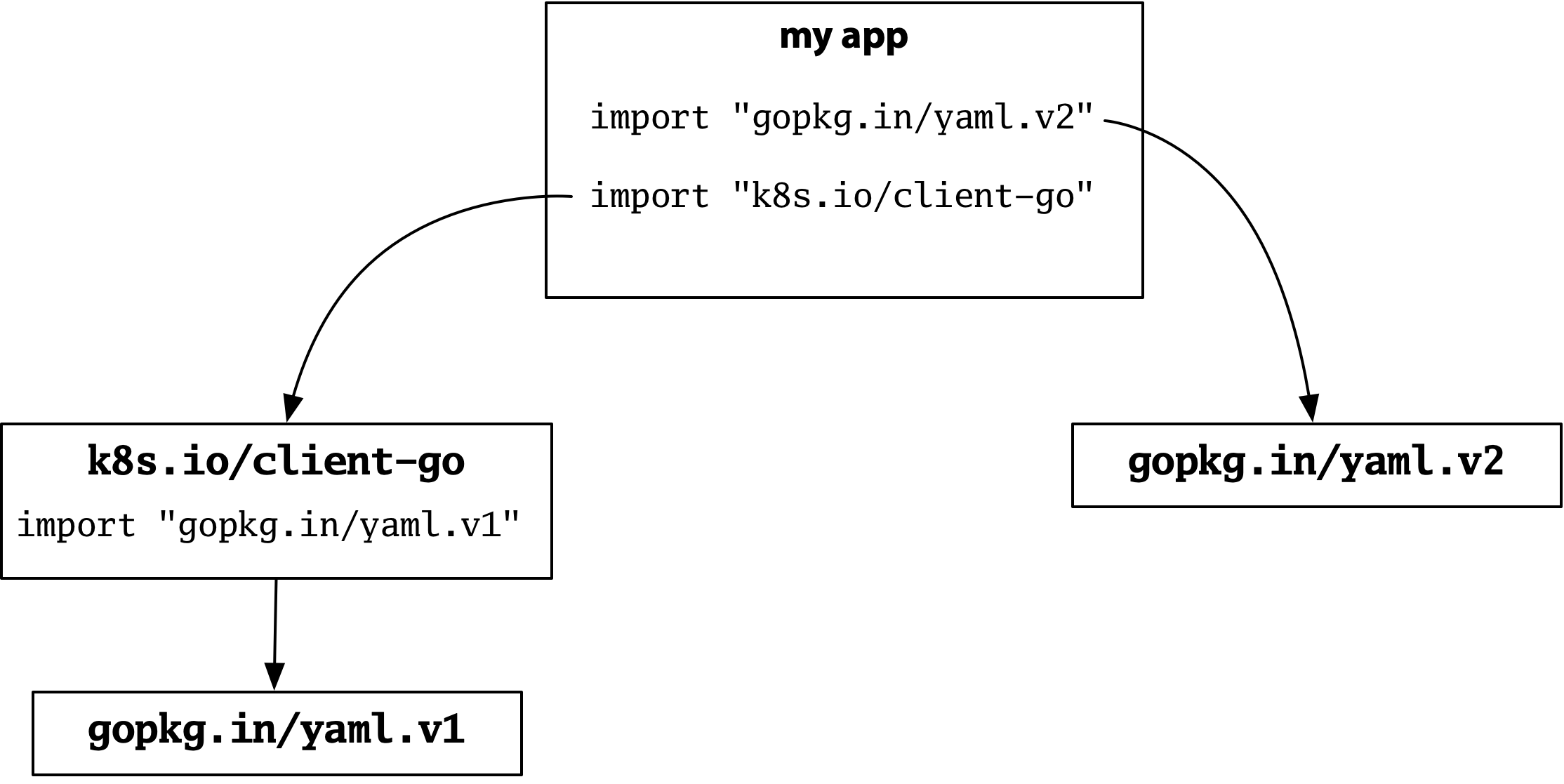
バージョン1とバージョン2には互換性のないAPIがありますが、インポートパスも異なるため、特定のインポートが何を意味するのか曖昧さはありません。Kubernetesはバージョン1を取得し、設定パーサーはバージョン2を取得し、すべてが機能します。
Depはこのモデルを放棄しました。yamlパッケージのバージョン1とバージョン2は同じインポートパスを持つようになり、競合が発生します。同じインポートパスを2つの互換性のないバージョンに使用することと、パッケージの一意性が組み合わさることで、以前は構築できたこのプログラムを構築することが不可能になります。
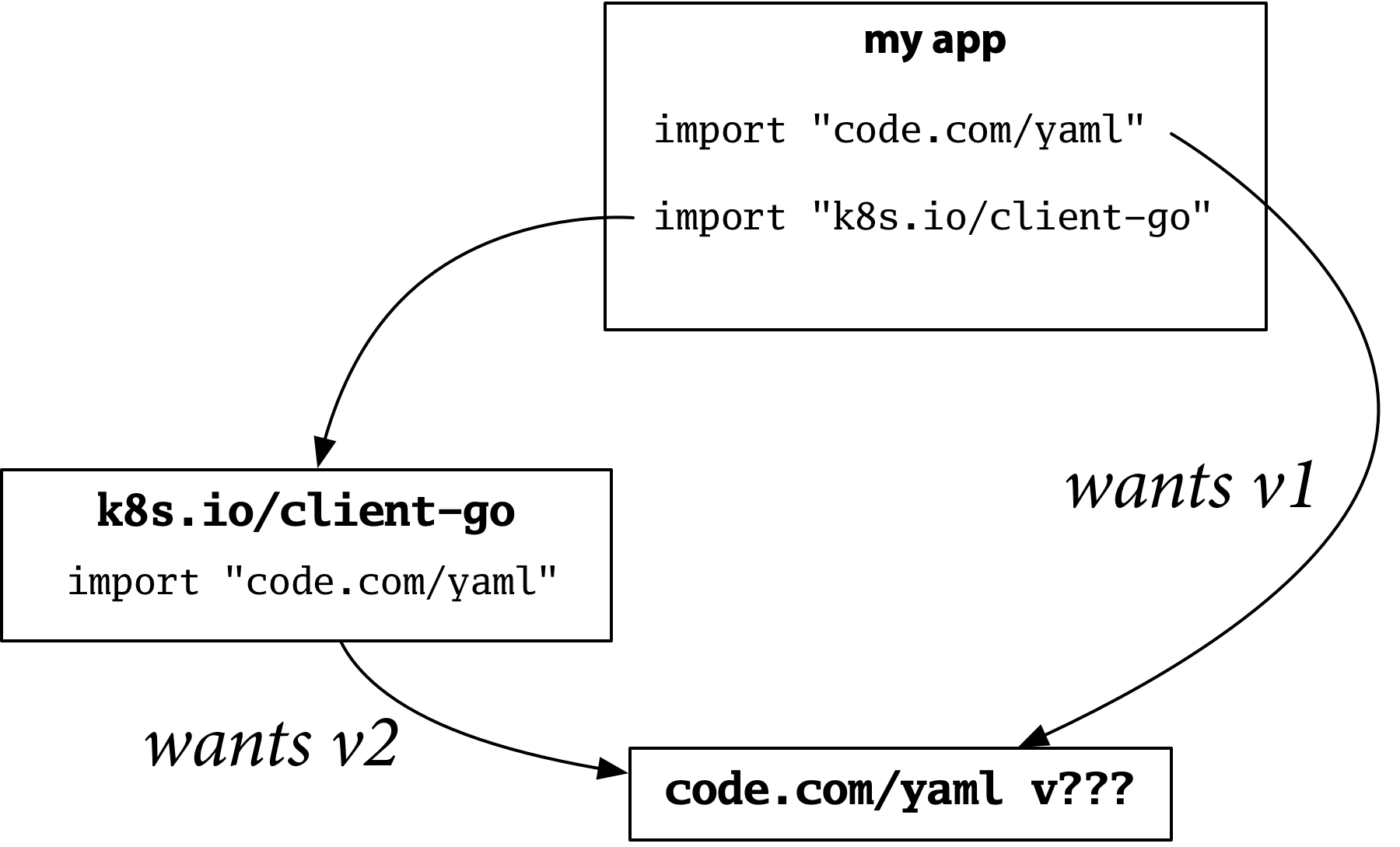
この問題を理解するのに時間がかかりました。なぜなら、「新しいAPIは新しいインポートパスを意味する」という慣習を長い間適用してきたため、それが当たり前だと思っていたからです。depの実験は、その慣習をよりよく理解するのに役立ち、私たちはそれに名前を付けました。「インポート互換性ルール」です。
「古いパッケージと新しいパッケージが同じインポートパスを持つ場合、新しいパッケージは古いパッケージと後方互換性がある必要があります。」
Goモジュール
depの実験でうまくいったこと、うまくいかなかったことから学んだことを踏まえ、vgoという新しい設計で実験しました。vgoでは、パッケージはインポート互換性ルールに従うため、パッケージの一意性を提供しつつ、先ほど見たようなビルドを壊すことなく構築できます。これにより、設計の他の部分も簡素化できました。
インポート互換性ルールを復元することに加えて、vgo設計のもう1つの重要な部分は、パッケージのグループの概念に名前を付け、そのグループがソースコードリポジトリの境界から分離できるようにすることでした。Goパッケージのグループの名前はモジュールなので、現在はGoモジュールシステムと呼んでいます。
Goモジュールは現在goコマンドに統合されており、ベンダーディレクトリをコピーして回る必要がなくなりました。
GOPATHの置き換え
Goモジュールに伴い、GOPATHはグローバルな名前空間としての役割を終えます。既存のGoの使用法とツールをモジュールに変換するほとんどの困難な作業は、このGOPATHからの移行によるものです。
GOPATHの基本的な考え方は、GOPATHディレクトリツリーが使用されているバージョンのグローバルな真実の源であり、ディレクトリ間を移動しても使用されているバージョンは変わらないというものです。しかし、グローバルGOPATHモードは、プロジェクトごとの再現可能なビルドという本番要件と直接衝突します。この要件自体は、Go開発とデプロイのエクスペリエンスを多くの重要な点で簡素化します。
プロジェクトごとの再現可能なビルドとは、プロジェクトAのチェックアウトで作業している場合、go.modファイルで定義されているように、プロジェクトAの他の開発者がそのコミットで取得するのと同じ依存関係のセットを取得することを意味します。プロジェクトBのチェックアウトで作業に切り替えると、今度はそのプロジェクトが選択した依存関係のバージョン、つまりプロジェクトBの他の開発者が取得するのと同じセットを取得します。しかし、それらはプロジェクトAとは異なる可能性があります。プロジェクトAからプロジェクトBに移動するときに依存関係のセットが変更されることは、開発をAとBの他の開発者と同期させるために必要です。単一のグローバルGOPATHはもう存在できません。
モジュールの採用の複雑さのほとんどは、単一のグローバルGOPATHが失われたことに直接起因しています。パッケージのソースコードはどこにありますか?以前は、答えはほとんどの人がめったに変更しないGOPATH環境変数にのみ依存していました。現在、答えは作業中のプロジェクトによって異なります。これは頻繁に変更される可能性があります。この新しい慣習のためにすべてを更新する必要があります。
ほとんどの開発ツールは、Goソースコードを見つけてロードするためにgo/buildパッケージを使用しています。私たちはそのパッケージが機能し続けるようにしましたが、APIはモジュールを想定しておらず、APIの変更を避けるために追加した回避策は望ましいよりも遅いです。代わりに、golang.org/x/tools/go/packagesという代替品を公開しました。開発ツールはこれを使用すべきです。これはGOPATHとGoモジュールの両方をサポートしており、より高速で使いやすいです。1、2回のリリースで標準ライブラリに移動するかもしれませんが、今のところgolang.org/x/tools/go/packagesは安定しており、使用準備が整っています。
Goモジュールプロキシ
モジュールがGo開発を簡素化する方法の1つは、パッケージのグループという概念と、それらが保存されている基盤となるソース管理リポジトリという概念を分離することです。
依存関係についてGoユーザーと話すと、企業でGoを使用しているほとんどすべての人が、使用できるコードをより適切に制御するために、go getパッケージのフェッチを自社のサーバー経由でルーティングする方法を尋ねました。そして、オープンソース開発者でさえ、依存関係が予期せず消えたり変更されたりして、ビルドが壊れることを懸念していました。モジュール以前は、ユーザーはgoコマンドが実行するバージョン管理コマンドを傍受するなど、これらの問題に対して複雑な解決策を試みていました。
Goモジュールの設計により、特定のモジュールバージョンを要求できるモジュールプロキシの概念を簡単に導入できます。
企業は、許可されるものやキャッシュされたコピーがどこに保存されるかについて独自のルールを持つモジュールプロキシを簡単に実行できるようになりました。オープンソースのAthensプロジェクトはまさにそのようなプロキシを構築しており、Aaron SchlesingerはGophercon 2019でそれについて講演しました。(ビデオが公開されたらここにリンクを追加します。)
個々の開発者やオープンソースチーム向けに、GoogleのGoチームはすべてのオープンソースGoパッケージの公開ミラーとして機能するプロキシを立ち上げました。Go 1.13では、モジュールモードの場合、このプロキシがデフォルトで使用されます。Katie HockmanはGophercon 2019でこのシステムについて講演しました。
Goモジュールのステータス
Go 1.11はモジュールを実験的なオプトインプレビューとして導入しました。私たちは実験と簡素化を続けています。Go 1.12では改良が出荷され、Go 1.13ではさらに多くの改良が出荷されます。
モジュールは現在、ほとんどのユーザーに役立つと信じる段階にありますが、まだGOPATHをシャットダウンする準備はできていません。私たちは実験、簡素化、改訂を続けます。
私たちは、Goユーザーコミュニティがほぼ10年間にわたるGOPATHに関する経験、ツール、ワークフローを築き上げてきたことを十分に認識しており、それらをすべてGoモジュールに変換するには時間がかかります。
しかし、繰り返しますが、モジュールはほとんどのユーザーにとって非常にうまく機能するはずだと考えており、Go 1.13がリリースされたらぜひ試してみてください。
一例として、Kubernetesプロジェクトは多くの依存関係を持ち、それらを管理するためにGoモジュールに移行しました。あなたもそうできるはずです。もしできない場合は、バグレポートを提出して、何がうまくいかないのか、何が複雑すぎるのかを教えてください。私たちは実験し、簡素化します。
ツール
エラー処理、ジェネリクス、依存関係管理は少なくともあと数年かかり、当面はこれらに焦点を当てていきます。エラー処理はほぼ完了し、その次はモジュール、その次はジェネリクスになるかもしれません。
しかし、数年先、エラー処理、モジュール、ジェネリクスを実験し、簡素化し、出荷し終えた後を想像してみましょう。その次は?未来を予測するのは非常に困難ですが、これら3つが出荷されれば、それが大きな変更の新しい静穏期の始まりを告げるかもしれません。その時点での私たちの焦点は、おそらくGo開発を改善されたツールで簡素化することに移るでしょう。
一部のツール開発はすでに進行中であり、この投稿はその点について考察して終わります。
Goコミュニティの既存のすべてのツールがGoモジュールを理解するのを助ける中で、私たちは、それぞれが1つの小さな仕事をするたくさんの開発ヘルパーツールがユーザーにうまく機能していないことに気づきました。個々のツールは結合するのが難しすぎ、呼び出すのが遅すぎ、使用するのにあまりにも異なっていたからです。
私たちは、最も一般的に必要とされる開発ヘルパーを1つのツール、現在のgopls(「Go、プリーズ」と発音)に統一する取り組みを開始しました。GoplsはLanguage Server Protocol (LSP)を話し、LSPサポートを持つ統合開発環境やテキストエディタ(現時点ではほぼすべて)で動作します。
Goplsは、Goプロジェクトの焦点が、go vetやgorenameのようなスタンドアロンのコンパイラのようなコマンドラインツールを提供するだけでなく、完全なIDEサービスも提供するように拡大したことを示しています。Rebecca Stamblerは、Gophercon 2019でgoplsとIDEに関する詳細な講演を行いました。(ビデオが利用可能になり次第、ここにリンクを追加します。)
goplsの後には、go fixを拡張可能な方法で復活させるアイデアや、go vetをさらに役立つものにするアイデアもあります。
コーダ
これがGo 2への道です。私たちは実験し、簡素化します。そして、実験し、簡素化します。そして出荷します。そして、実験し、簡素化します。そして、すべてを繰り返します。道が堂々巡りをしているように見えたり感じられたりするかもしれません。しかし、実験し、簡素化するたびに、Go 2がどのようなものであるべきかについて少しずつ学び、さらに一歩近づきます。tryや最初の4つのジェネリクスの設計、depのような放棄された実験でさえも時間の無駄ではありません。それらは、出荷する前に何を簡素化する必要があるかを学ぶのに役立ち、場合によっては、私たちが当然のことと思っていたことをよりよく理解するのに役立ちます。
ある時点で、私たちは十分に実験し、十分に簡素化し、十分に出荷したことに気づき、Go 2を手に入れるでしょう。
この道を歩む上で、実験し、簡素化し、出荷し、道を見つけるのを助けてくれたGoコミュニティの皆さんに感謝します。
次の記事: コントリビューターサミット 2019
前の記事: なぜジェネリクスなのか?
ブログインデックス